从 RoboOS/RoboBrain 到 Fast-WAM:机器人 Agent 的系统分解与低延迟世界动作模型
2026-05-20组会
根据 2026-05-20 组会分享整理 | 分享人:李卓然、王启源
5 月 20 日的组会围绕机器人智能体中的两个关键问题展开:一个是“复杂机器人 Agent 系统到底应该怎样拆开”,另一个是“World Action Model 是否真的需要在测试时先想象未来再执行动作”。
本期两篇分享分别由李卓然同学和王启源同学带来。前者梳理了 BAAI RoboOS / RoboBrain 系列工作,从 Agent 架构、Brain、训练、记忆四个层面理解机器人系统;后者阅读 Fast-WAM,讨论如何在保留世界模型训练收益的同时,显著降低推理时延。
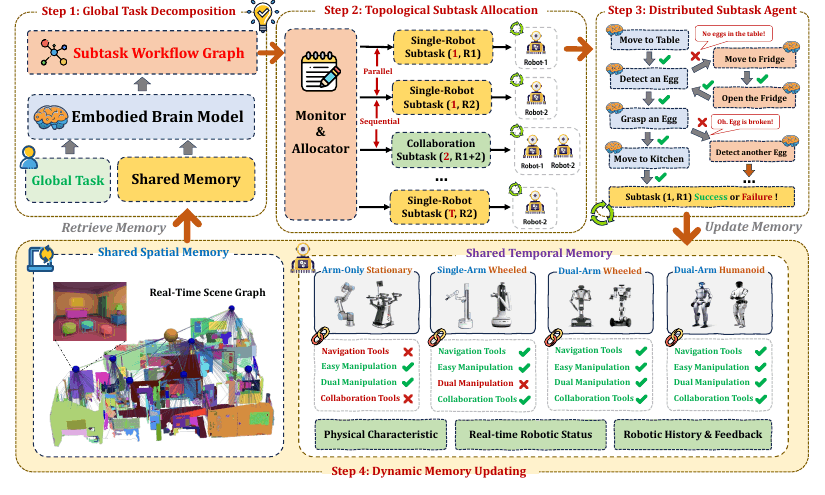
RoboOS 任务执行流程
一、RoboOS / RoboBrain:一个机器人 Agent 系统怎么被拆开
李卓然同学的分享并不把 RoboOS / RoboBrain 看成单篇论文,而是把这一系列工作作为一个“机器人 Agent 全家桶”来理解。沿着这条线,系统大致可以拆成四层:
|
层次 |
代表工作 |
角色 |
|
Agent 架构 |
RoboOS, RoboOS-NeXT |
任务分解、DAG 调度、多机器人协作 |
|
Brain |
RoboBrain 1.0 / 2.0 / 2.5 |
视觉理解、规划、空间推理、过程价值估计 |
|
Training |
ShareRobot, Reason-RFT, OmniSAT, Robo-Dopamine |
让模型学会推理、动作 token 化、进度评估 |
|
Memory |
Shared Memory, STEM, RoboMemory |
保存世界状态、历史轨迹和经验,并在执行时检索 |
这个拆法的核心价值在于:它把一个端到端机器人系统拆成了可以调试、可以替换、可以评估的模块,而不是把所有能力都压进一个黑盒 VLA。
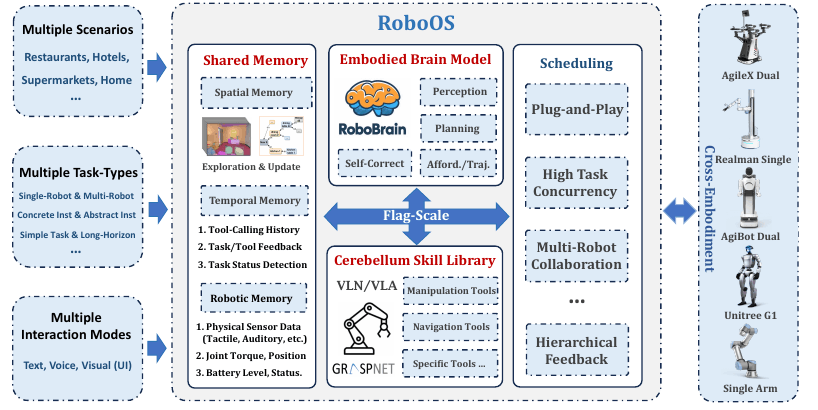
RoboOS 总体架构
1. RoboOS:从“聊天式多 Agent”到可调度任务图
RoboOS 的基本设计可以概括为三部分:
Brain 在云端做高层理解和任务分解;Cerebellum / Skill Library 在机器人端执行导航、抓取和专用技能;Shared Memory 保存空间状态、执行历史和机器人状态。
一次任务的运行链路通常是:
- 输入全局任务;
- Brain 从 shared memory 中检索相关状态;
- 生成 reasoning trace 和 subtask DAG;
- Monitor 按拓扑依赖调度子任务;
- Robotic Agent 调用工具或技能执行;
- 执行反馈和场景变化写回 memory。
这里最关键的不是“多个 agent 互相聊天”,而是系统生成的是可调度、可检查、可回放的任务图。对于多机器人场景,这一点尤其重要:谁能做什么、谁正在执行、哪些步骤有依赖、失败后如何恢复,都需要从隐式对话变成显式状态。
2. RoboBrain:从 2D 操作到 3D 空间与过程价值
RoboBrain 1.0 主要围绕三类输出展开:planning、affordance 和 trajectory。也就是说,模型不仅要把任务拆成步骤,还要指出可交互区域,并给出 2D 操作轨迹或关键点。
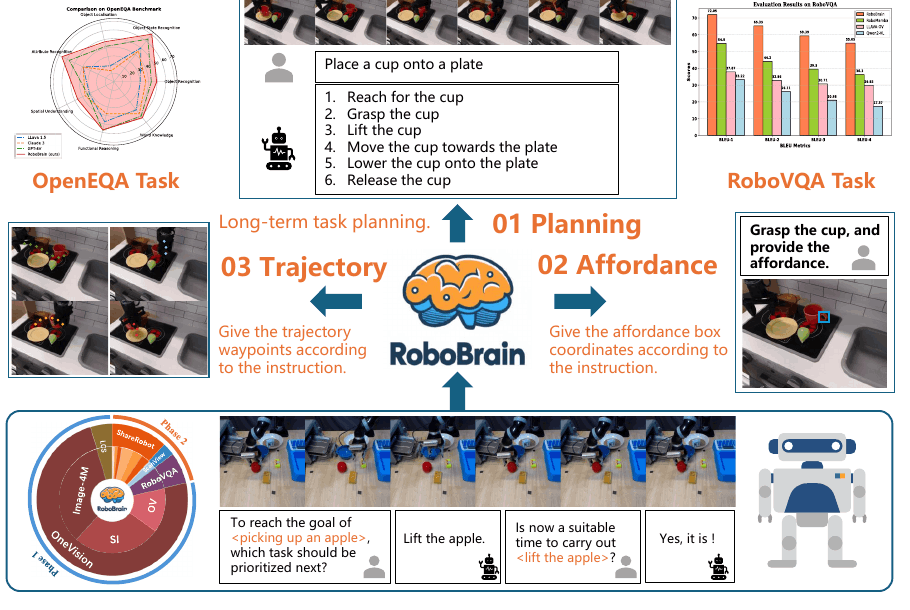
RoboBrain 1.0 的 planning / affordance / trajectory
RoboBrain 2.0 进一步走向更通用的 embodied reasoning model:输入侧支持多图、长视频、高分辨率和场景信息;输出侧覆盖规划、空间坐标、轨迹与 reasoning。训练上,它引入更大规模的 spatial / temporal / robotic data,并在后训练中借鉴 Reason-RFT 的思路,即先用 CoT-SFT 激活推理格式,再用 GRPO / RFT 强化。
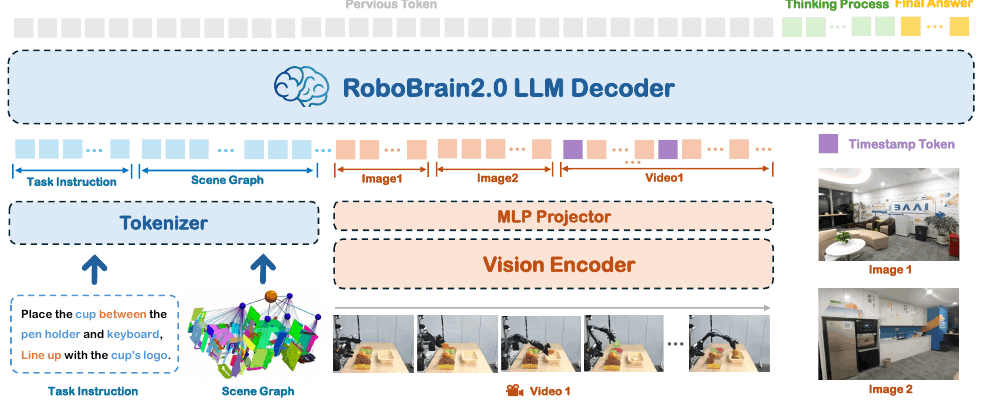
RoboBrain 2.0 架构
到了 RoboBrain 2.5,升级重点变成两个关键词:Precise 3D Spatial Reasoning 和 Dense Temporal Value Estimation。前者把空间能力从 2D referring / keypoint 推进到 3D referring、measuring 和 trace generation;后者则让模型对执行过程给出更密集的“进度估计”,可以作为 reward 或 critic signal。
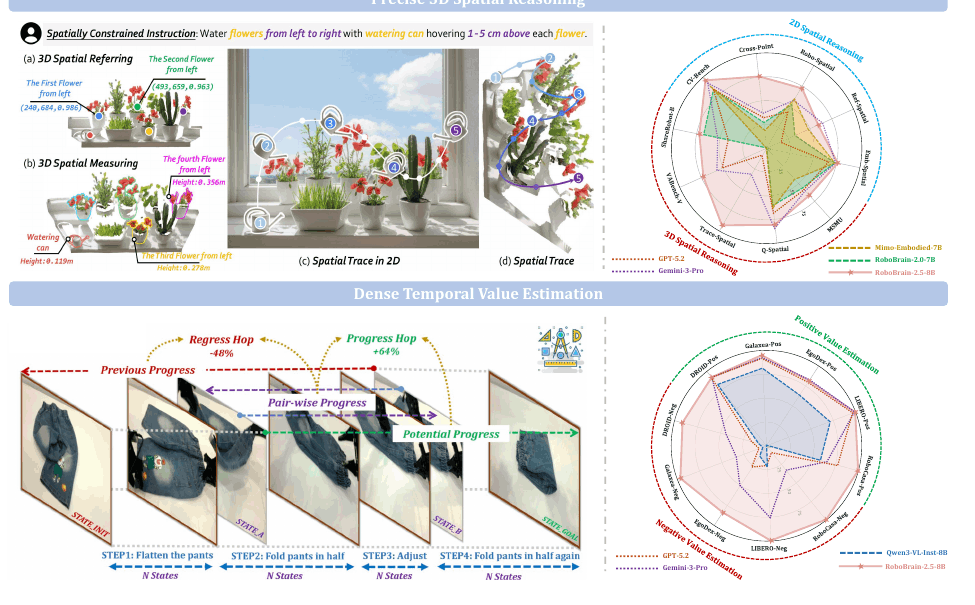
RoboBrain 2.5:3D 空间推理与过程价值估计
这意味着 Brain 不只是会“给计划”,还开始具备判断动作是否真正推进任务的能力。对于长程任务而言,这种过程价值估计很重要,因为最终成功与否往往太稀疏,无法支撑每一步决策。
3. Reason-RFT:为什么不能直接上 RL
在 RoboBrain 系列的训练线索中,Reason-RFT 是一个值得单独拎出来看的环节。它采用两阶段策略:
- CoT-SFT:先用少量高质量推理数据激活 reasoning format;
- GRPO / RFT:再通过 format reward 和 accuracy reward 强化。
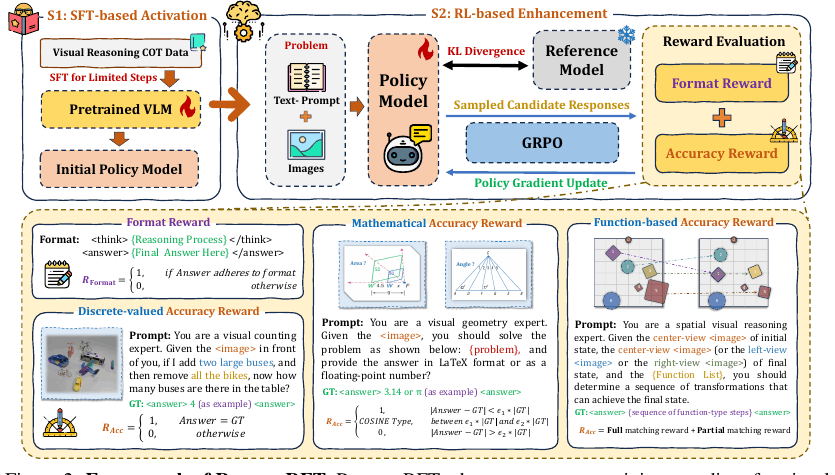
Reason-RFT 两阶段训练
背后的直觉是:小模型如果直接 RL,容易学会“格式正确”这类便宜奖励,而不一定真的获得任务推理能力。先经过 CoT-SFT,模型至少知道应该以什么形式展开推理,后续 RL 才更稳定。
4. OmniSAT:连续动作如何变成可预测的 token
RoboBrain-X0 的工程发布中提到其 includes RoboBrain 2.0 and OmniSAT。X0 本身目前更像官方工程版本,而不是独立论文;真正值得技术上拆解的是 OmniSAT 如何把连续动作接到自回归模型输出上。
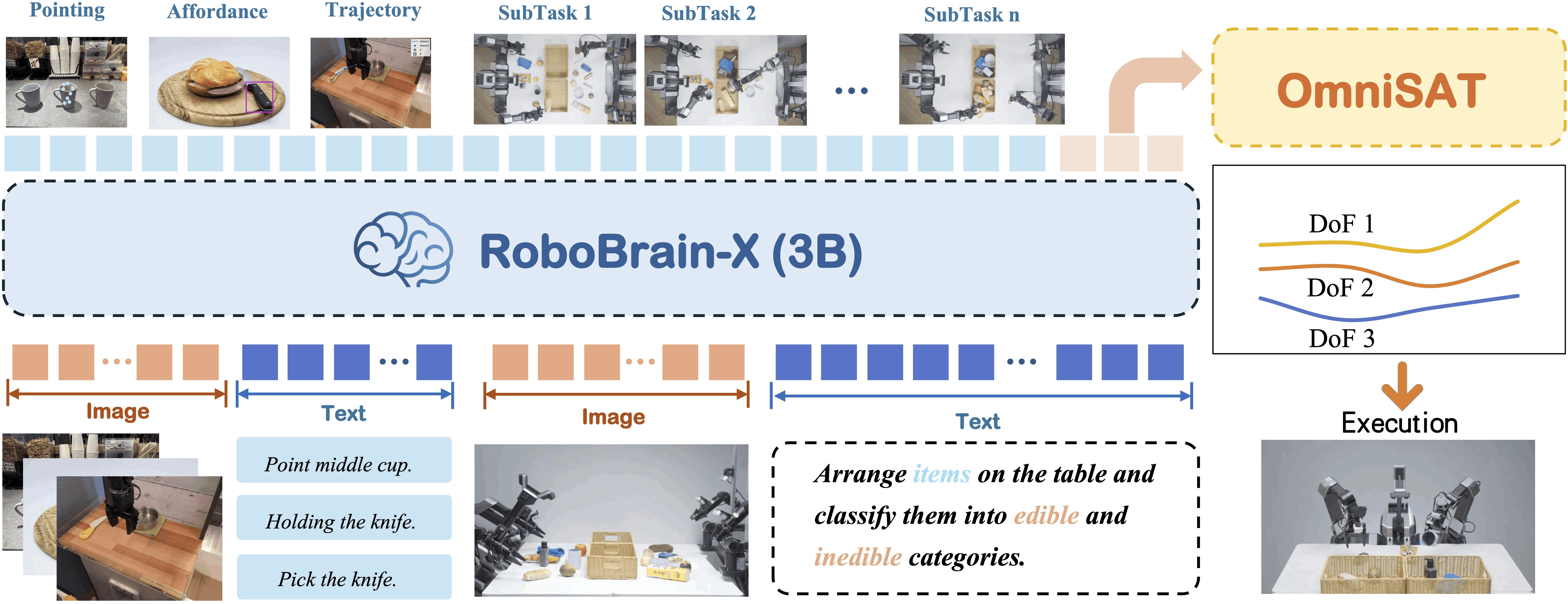
RoboBrain-X0 与 OmniSAT
OmniSAT 的 action tokenizer 可以理解为以下流程:
- 将连续轨迹归一化;
- 用 B-spline 把不同长度的轨迹拟合成固定长度控制点;
- 按 position、rotation、gripper 分组;
- 对每组使用 residual quantization 生成离散 token;
- 自回归 VLA 预测 token,再解码回连续动作。
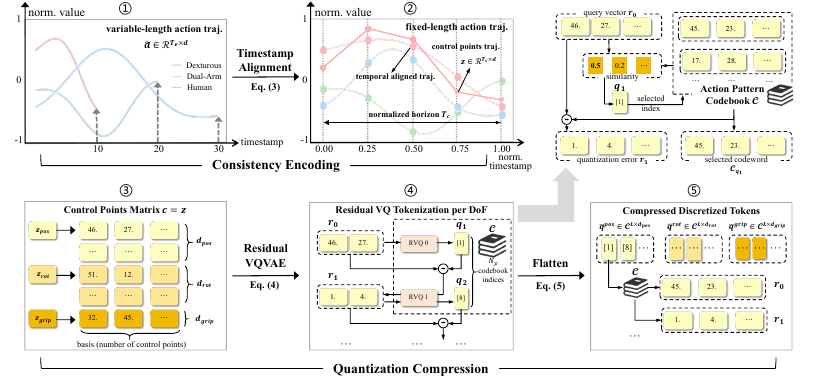
OmniSAT action tokenizer
对于单臂动作 [x, y, z, roll, pitch, yaw, gripper],position 组对应 x/y/z 控制点,rotation 组对应 roll/pitch/yaw 控制点,gripper 单独成组。分组不是模型自动发现的,而是按动作向量的物理语义进行切片。这样做的原因也很直接:平移、旋转和夹爪开合的数值分布与物理含义不同,用独立 codebook 量化更合理。
5. Memory:机器人 Agent 的外部世界状态
长程机器人任务中,如果模型每一步都只从当前图像重新猜世界状态,很容易出问题:物体可能被遮挡,上一轮动作结果可能丢失,多机器人状态需要同步,失败恢复也需要历史路径。因此 memory 不是“提示词增强”,而是机器人 Agent 的外部世界状态。
RoboOS 的 Shared Memory 包含三类:
|
记忆类型 |
内容 |
|
Spatial |
dynamic scene graph:物体、位置、空间和功能关系 |
|
Temporal |
task feedback、tool-calling history、执行日志 |
|
Robotic |
机器人状态、能力、关节、电量和连接状态 |
RoboOS-NeXT 将 memory 进一步形式化为 STEM:
M(t) = (S(t), T(t), E(t))
其中 Spatial 是 scene tree + object relation graph,Temporal 是 timestamped queue,Embodiment 是 robot profile,包括位置、能力、约束和状态。
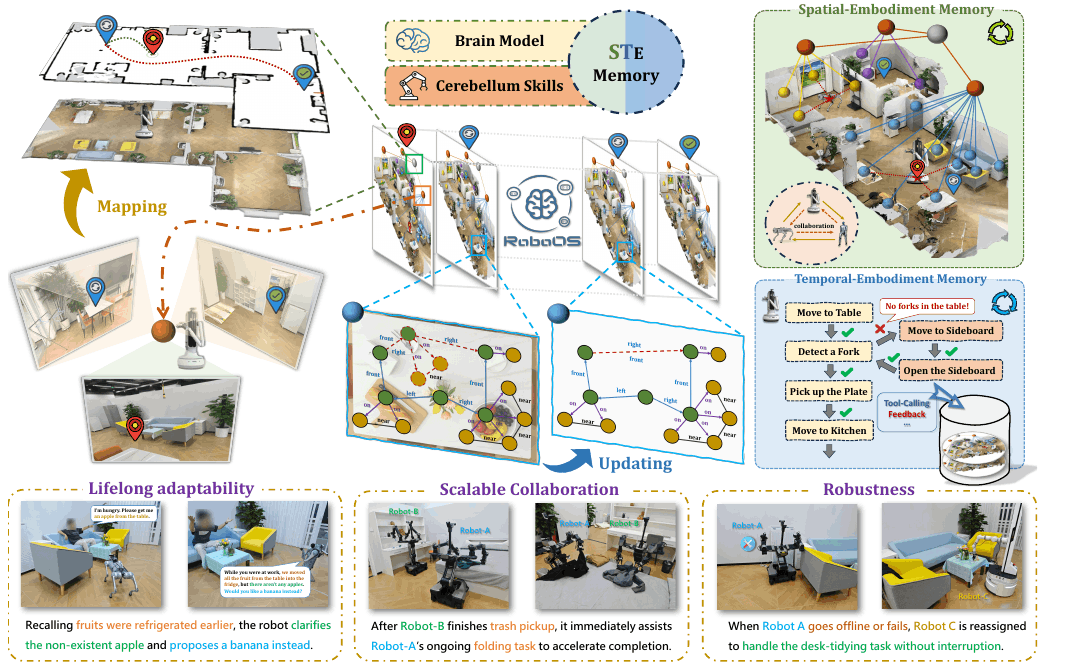
RoboOS-NeXT STEM memory
RoboMemory 则给出了更具体的 memory 管理方案:Temporal 使用 FIFO buffer,并在满时压缩旧 summary;Spatial 使用 dynamic KG,并支持局部 sub-KG 检索与更新;Semantic 和 Episodic memory 则以自然语言条目、任务轨迹、动作和反馈为核心,通过 vector DB 检索。
如果要做一个最小复现系统,分享中给出的路线是:
- Planner:LLM / VLM 生成下一步动作;
- Temporal FIFO:记录最近步骤,满了后总结压缩;
- Spatial KG:维护物体、关系和位置;
- Semantic / Episodic vector DB:保存规则与成功/失败轨迹;
- Retrieval:每步按 query 检索 memory 拼进 planner;
- Critic:第二步以后检查动作,避免无限重规划。
这条路线非常适合用来验证 memory 到底有没有用:如果去掉 memory,系统在哪些长程、多物体、多机器人场景中明显退化,就能看得很清楚。
二、Fast-WAM:World Action Model 是否需要测试时想象未来
王启源同学分享的 Fast-WAM 聚焦另一个问题:World Action Model 的性能收益,到底来自训练时的视频预测,还是来自推理时显式生成未来帧?

Fast-WAM 论文信息
主流 WAM 架构大致可以分成两类:
|
类型 |
代表工作 |
基本思路 |
|
Joint |
Motus, Cosmos Policy, DreamZero |
视频 token 和动作 token 联合建模、联合去噪 |
|
IDM |
LingBot-VA |
先预测视觉未来,再通过 inverse dynamics 解码动作 |
Fast-WAM 的核心判断是:训练时的视频目标很重要,因为它给模型注入物理先验和动作表征;但推理时不一定要完整生成未来视频。也就是说,模型可以在训练中“学会想象”,但在部署时不必真的“慢慢想完再动”。
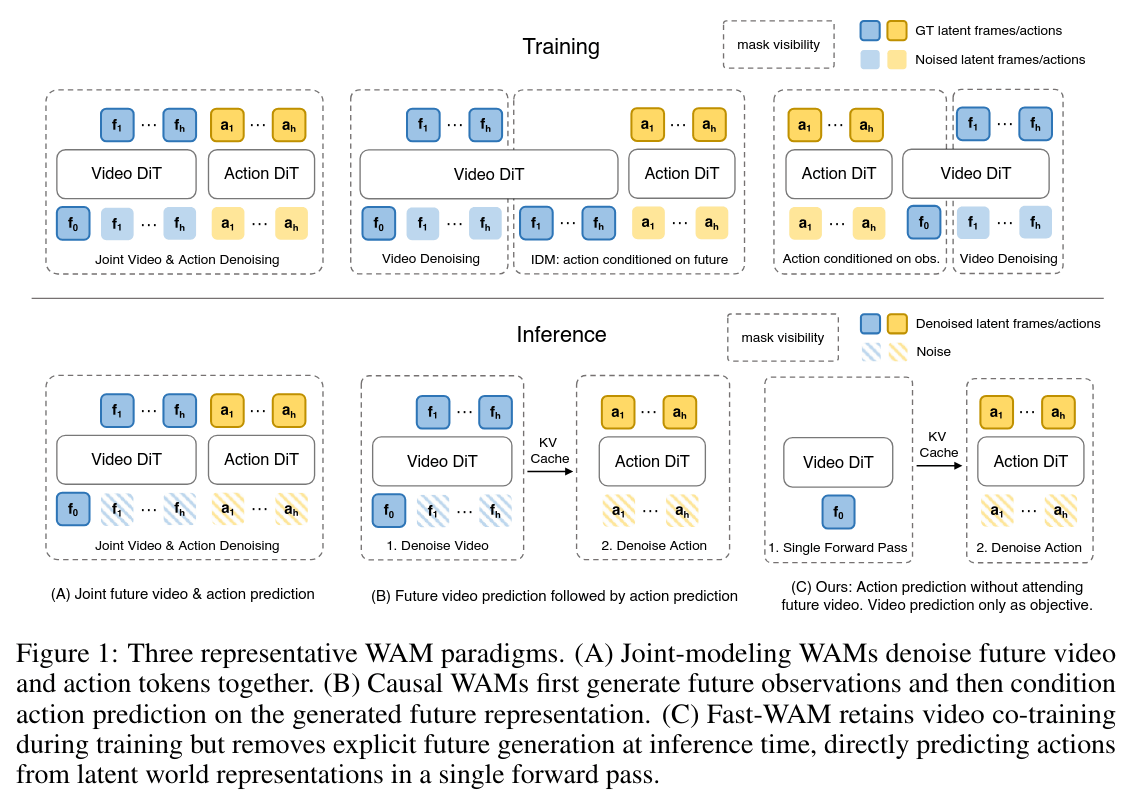
三类 WAM 范式对比
1. 现有路线的瓶颈:强但慢
以 LingBot-VA 为例,它采用 dual-stream 架构:Video Model 负责视觉动力学预测,基于历史观测预测未来;IDM 则从期望的视觉转换中解码动作。工程上,它通过 KVCache、Video Model 与 Action Model 计算/执行 overlap、FDM 锚定等方式优化,部署时延约 320 ms;再通过不完全去噪,将 s = 0.5 时缩减到 3 步 denoise。
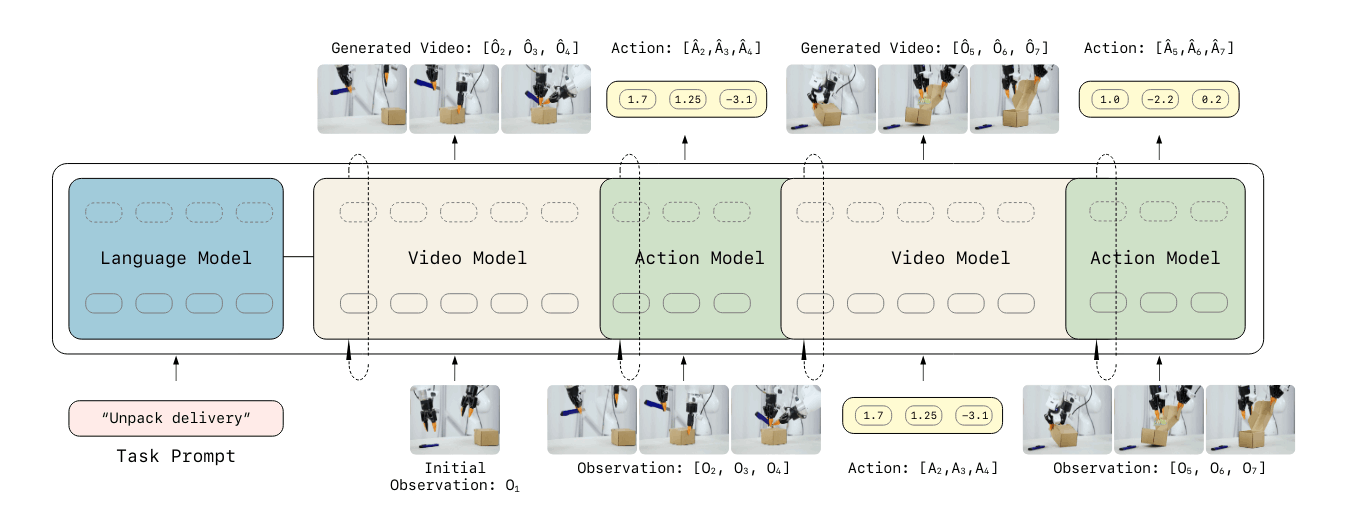
LingBot-VA dual stream
Motus 则是 joint 路线代表,使用 tri-joint 架构:一个 unified transformer 在单个 chunk 内通过 joint attention 共享视频、动作和语言知识。它的问题同样在部署侧,推理时延也在 300 ms 以上。
Motus tri-joint 架构
这些方法都说明了 WAM 的有效性,但也把问题暴露出来:如果机器人每一步都要进行迭代视频去噪,那么动作闭环会被明显拖慢。
2. Fast-WAM 的设计:训练时联合去噪,推理时只取 latent world representation
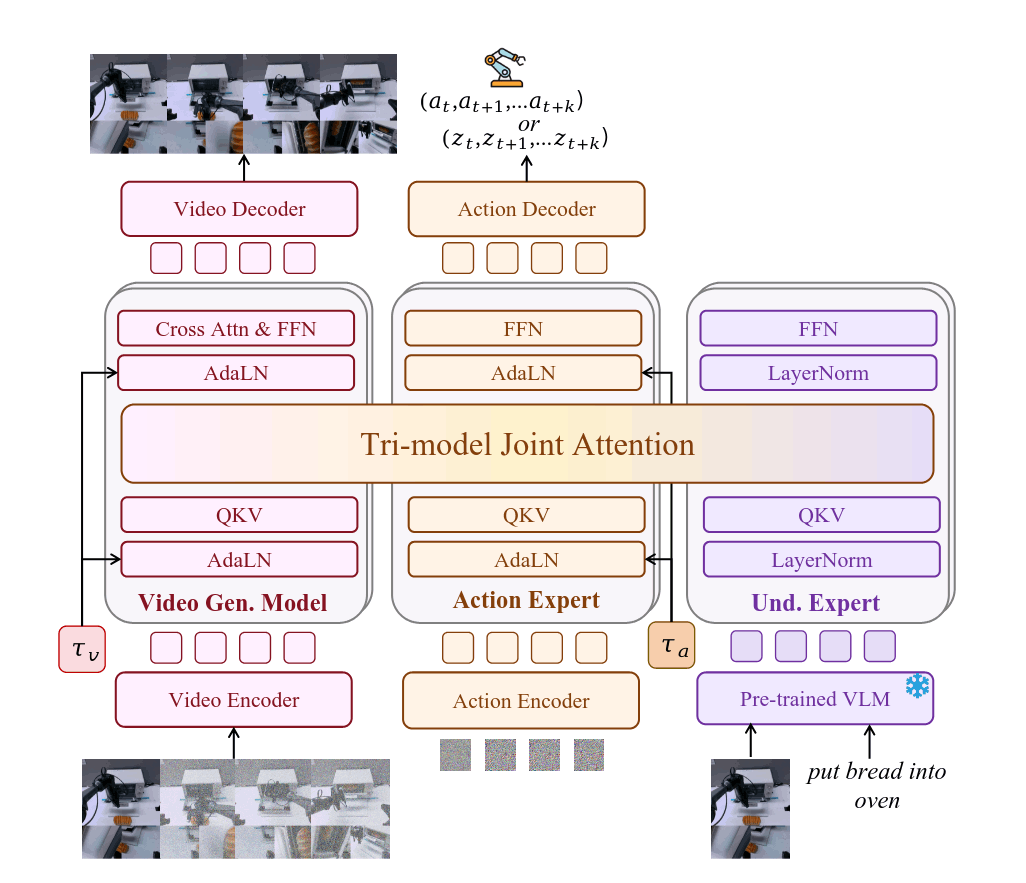
Fast-WAM 的架构可以概括为一句话:训练时像 joint WAM,推理时不显式生成未来视频。
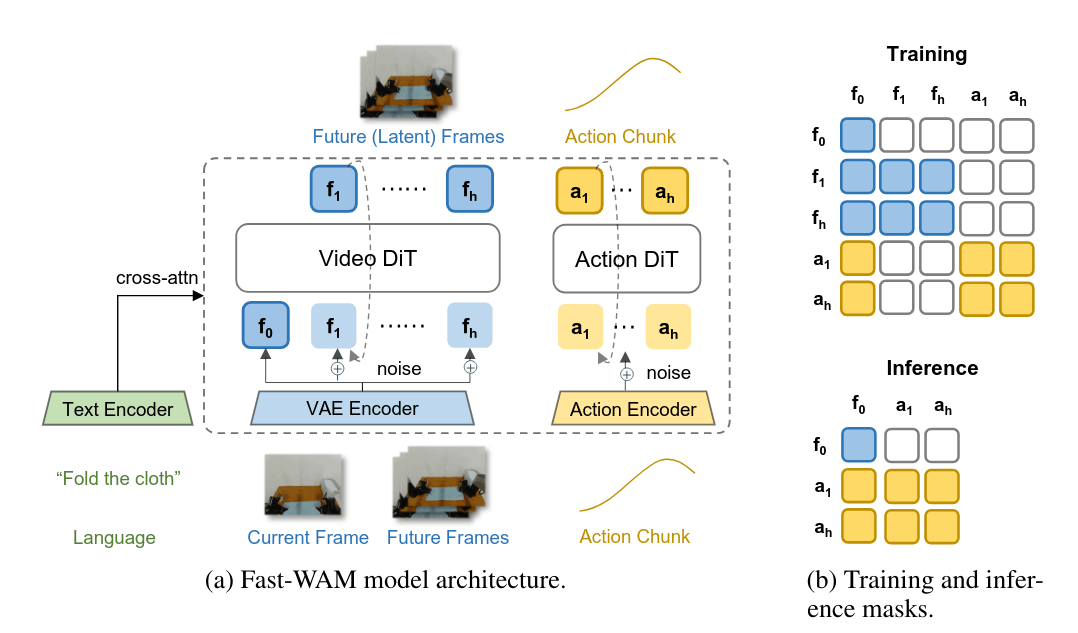
Fast-WAM 模型架构
具体地,它以 Wan2.2-5B 为 backbone,包含 VAE Encoder 和 Text Encoder;Video DiT 约 5B,Action DiT 约 1B,二者采用相似的 MoT 结构。训练时,Video DiT 与 Action DiT 联合去噪,视频 token 仍然作为学习物理先验的重要目标;推理时,Video DiT 只 forward 一轮,不做完整去噪,Action DiT 只能看到当前帧对应的 latent 信息,然后直接预测 action chunk。
这一点正是 Fast-WAM 的技术取舍:保留视频 co-training 带来的表征收益,去掉测试时显式 future generation 的主要开销。
3. 实验结果:co-training 重要,test-time imagination 未必必要
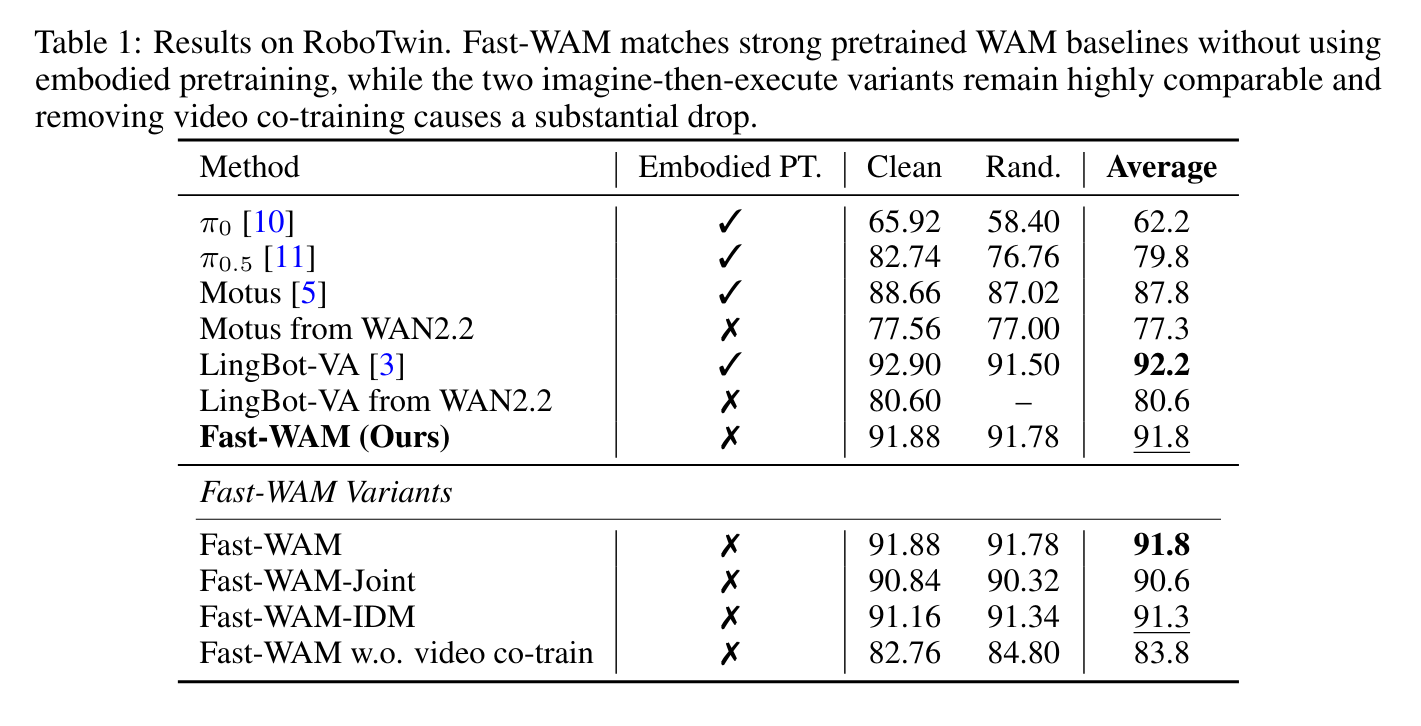
在 RoboTwin 上,Fast-WAM 在没有 embodied pretraining 的情况下达到 91.8 平均分,接近使用 embodied pretraining 的 LingBot-VA 92.2,并明显高于 Motus from WAN2.2 的 77.3。消融中,去掉 video co-train 后平均分从 91.8 降到 83.8,说明训练时的视频目标确实是关键来源之一。
RoboTwin 结果与消融
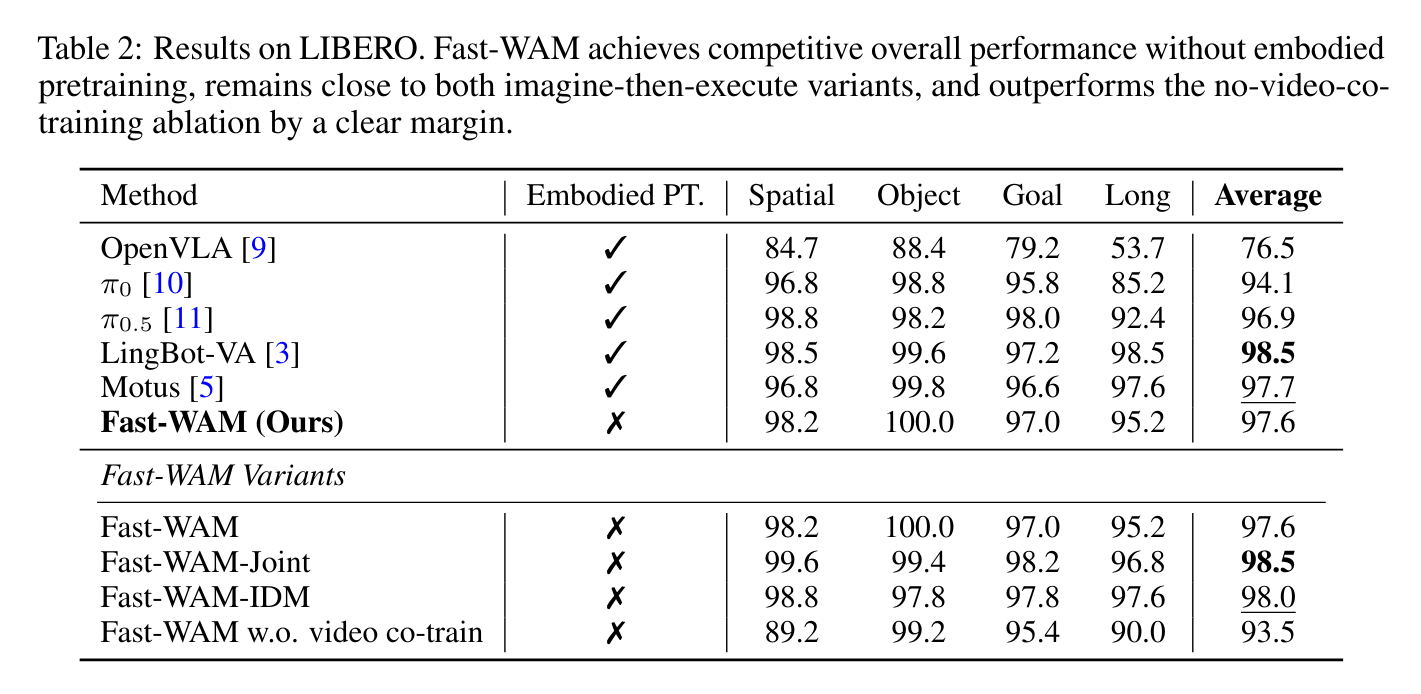
在 LIBERO 上也能看到类似趋势:Fast-WAM 平均 97.6,接近 Motus 的 97.7 和 LingBot-VA 的 98.5;去掉 video co-train 后降到 93.5。Fast-WAM-Joint 和 Fast-WAM-IDM 变体在 LIBERO 上分别为 98.5 和 98.0,说明“想象未来再执行”不是完全无效,而是其边际收益需要和时延成本一起看。
LIBERO 结果与消融
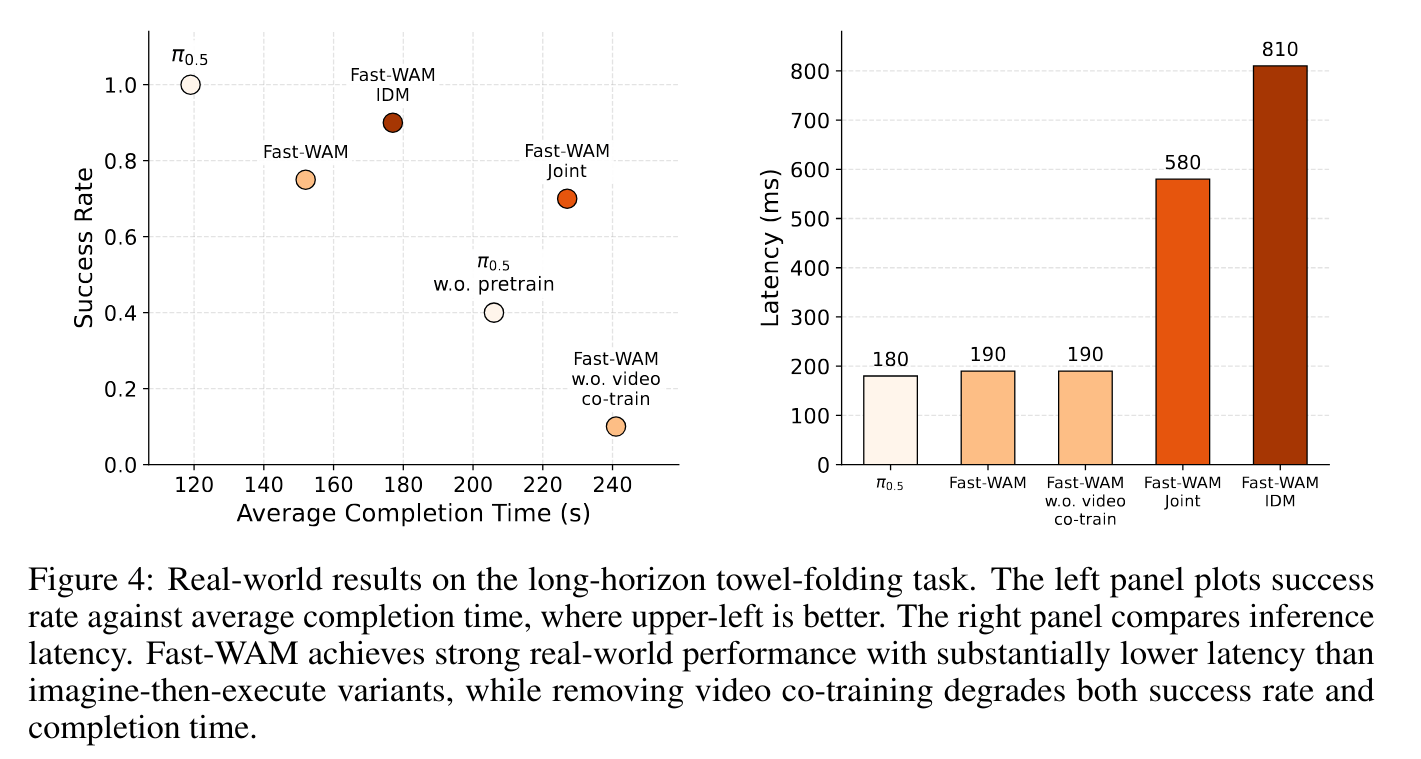
真实毛巾折叠任务中,时延差距更直观。图中 Fast-WAM 的推理时延约 190 ms,Fast-WAM-Joint 约 580 ms,Fast-WAM-IDM 约 810 ms。换句话说,显式 future denoising 会把动作闭环拖到数倍开销,而 Fast-WAM 仍能保持较强真实任务表现。
真实毛巾折叠任务:成功率、完成时间与时延
Fast-WAM 的实验设置也值得注意:分享中提到其使用单张 5090D 推理,每次预测 32 步 action,action denoise 为 10 步,视频在时间上做 4x 采样。对于部署讨论而言,这些细节比单纯看成功率更重要,因为机器人系统最终要面对的是闭环频率、动作延迟和失败恢复。
4. 延伸对照:VLA 与外挂 World Model
分享最后还对照了 Pi0.7 一类 VLA + World Model 的路线:主 VLA 负责动作,14B BAGEL world model 提供 subgoal,High-Level Policy 生成 subtask,并通过 metadata 支持更多数据利用。
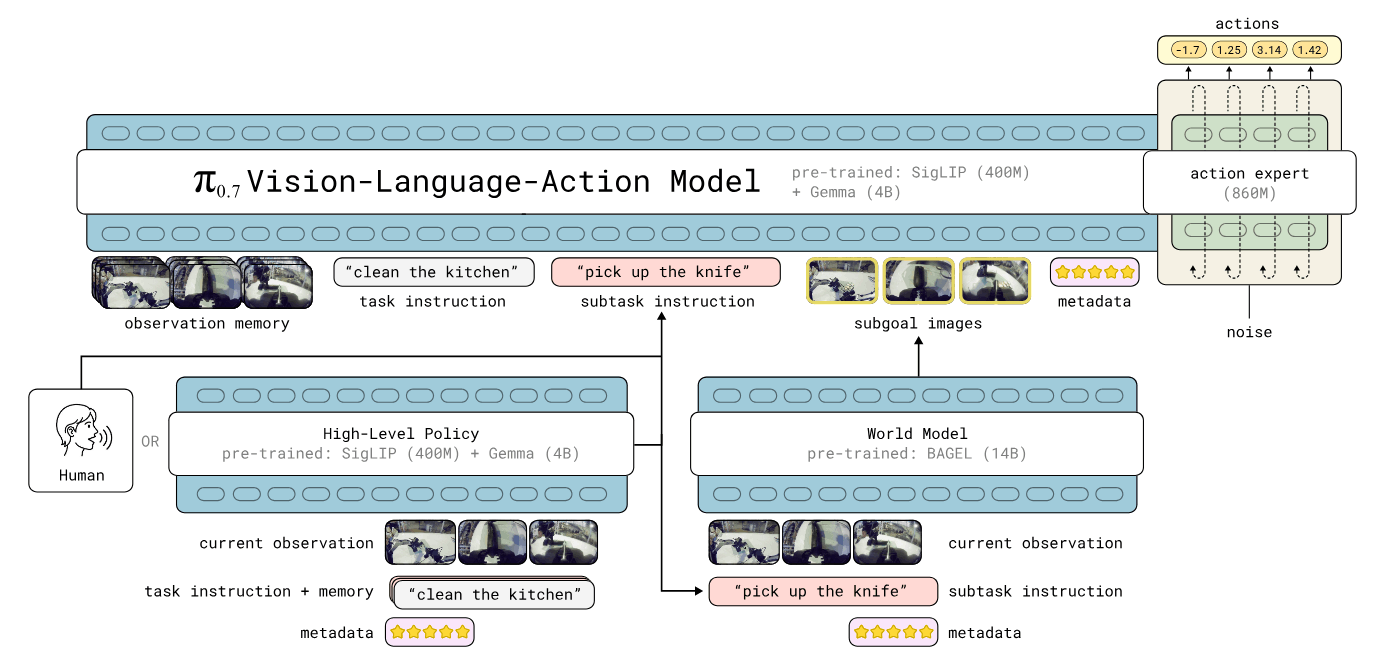
Pi0.7:VLA 与外挂 world model
这类路线的核心工程问题也落在时延上。分享中提到,其推理时延从 38 ms 到最坏 127 ms;对新增的 subgoal 和 subtask 开销,系统采用异步推理,subgoal / subtask 直接异步读取,不阻塞主动作链路,并在 subtask 变化或超过 4 秒时刷新。World Model 侧使用 4 张 H100 做 4 路张量并行,配合 8-bit 量化和 SageAttention,将 25 step 控制到约 1.25 s。
这和 Fast-WAM 的问题意识是一致的:world model 能带来更好的物理先验和长期目标,但在机器人闭环中,任何“想象”都必须被放进时延预算里。
三、两篇分享放在一起看:系统分解与推理时延是一体两面
这两篇分享看似主题不同,其实都在回答同一个问题:如何把机器人智能从“单个大模型能力”变成“可部署系统能力”。
RoboOS / RoboBrain 的答案是系统分解:把任务规划、DAG 调度、技能执行、memory 更新、critic / reward 拆成明确模块,让每一层都有可观测状态。它适合思考长程任务、多机器人协作和失败恢复。
Fast-WAM 的答案是推理路径重构:承认视频预测对表征学习有帮助,但尽量避免在部署时完整生成未来视频,把 world representation 的收益和动作闭环的时延预算重新平衡。
从工程视角看,一个可用的机器人 Agent 可能需要同时吸收这两类思路:
- 高层用类似 RoboOS 的结构,把任务拆成 DAG,并用 memory 保存世界状态和执行历史;
- 低层用类似 Fast-WAM 的方式,让动作模型获得 world model 训练收益,但在闭环控制中避免不必要的推理开销;
- 中间通过 critic、value estimation 或 dense progress signal 判断动作是否推进任务,减少长程任务中的盲目重规划。
如果用一句话总结本周组会:机器人 Agent 的关键不只是“模型更大”,而是系统能否把理解、记忆、规划、动作和反馈组织成一个低延迟、可调试、可恢复的闭环。
参考
- RoboOS: https://arxiv.org/abs/2505.03673
- RoboBrain 1.0: https://arxiv.org/abs/2502.21257
- RoboBrain 2.0: https://arxiv.org/abs/2507.02029
- RoboBrain 2.5: https://arxiv.org/abs/2601.14352
- Reason-RFT: https://arxiv.org/abs/2503.20752
- RoboMemory: https://arxiv.org/abs/2508.01415
- RoboOS-NeXT: https://arxiv.org/abs/2510.26536
- OmniSAT: https://arxiv.org/abs/2510.09667
- RoboBrain-X0: https://github.com/FlagOpen/RoboBrain-X0
- Fast-WAM: https://yuantianyuan01.github.io/FastWAM/

社区规范:仅讨论OpenHarmony相关问题。
更多推荐
 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)