开源鸿蒙具身智能PMC(筹)发表顶会论文: 提出具身智能场景下机器人端侧部署的VLA模型跨XPU评测与加速方法

第43届国际机器学习大会(ICML 2026)论文录用名单正式公布,开源鸿蒙具身智能PMC(筹)相关研究论文成功被大会接收。ICML是机器学习领域顶会,与NeurIPS、ICLR并称为领域三大会,本次入选成果是开源鸿蒙具身智能PMC(筹)在具身智能操作系统技术建设上迈出关键一步,为后续推进具身智能端侧推理优化与机器人产业化落地提供关键技术。
视觉-语言-动作模型(Vision-Language-Action Models, VLA)正在成为通用机器人感知、推理与控制的重要技术路线。与云端或桌面环境不同,真实机器人端侧部署需要在有限算力、功耗预算和硬件成本约束下,持续满足实时控制频率与任务成功率要求。如何系统评估不同VLA模型在GPU、NPU等异构XPU硬件上的实际表现,并进一步降低推理延迟、能耗和部署成本,是具身智能规模化落地必须解决的关键问题。
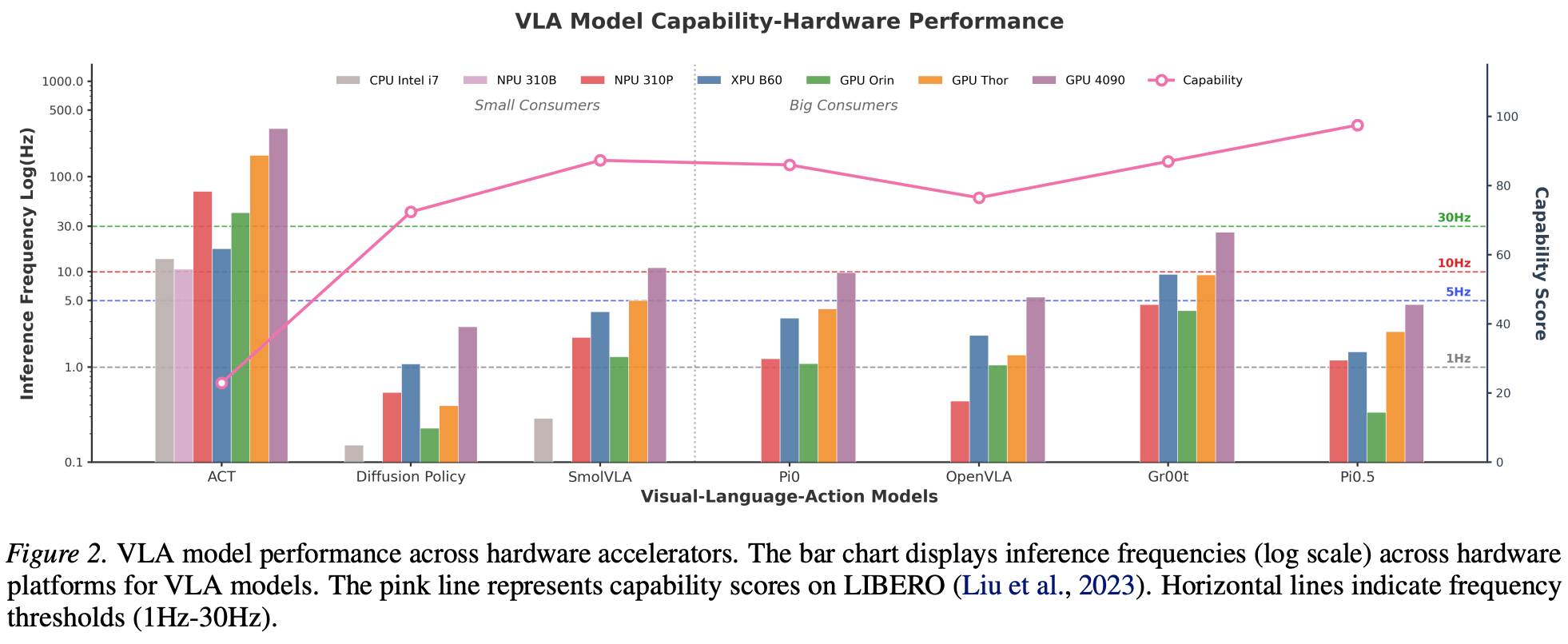
针对上述问题,本论文提出面向机器人部署的VLA模型-XPU硬件协同分析与加速框架。工作首先构建跨硬件VLA-Leaderboard评测榜单,围绕成本、能耗和延迟三个维度,对不同VLA模型与硬件平台组合进行系统化实测与对比。评测结果表明,合适规模的边缘设备在满足机器人控制频率要求的同时,能够在成本/能耗效率上取得优于桌面级旗舰GPU的综合表现,为机器人端侧硬件选型提供了可量化依据。
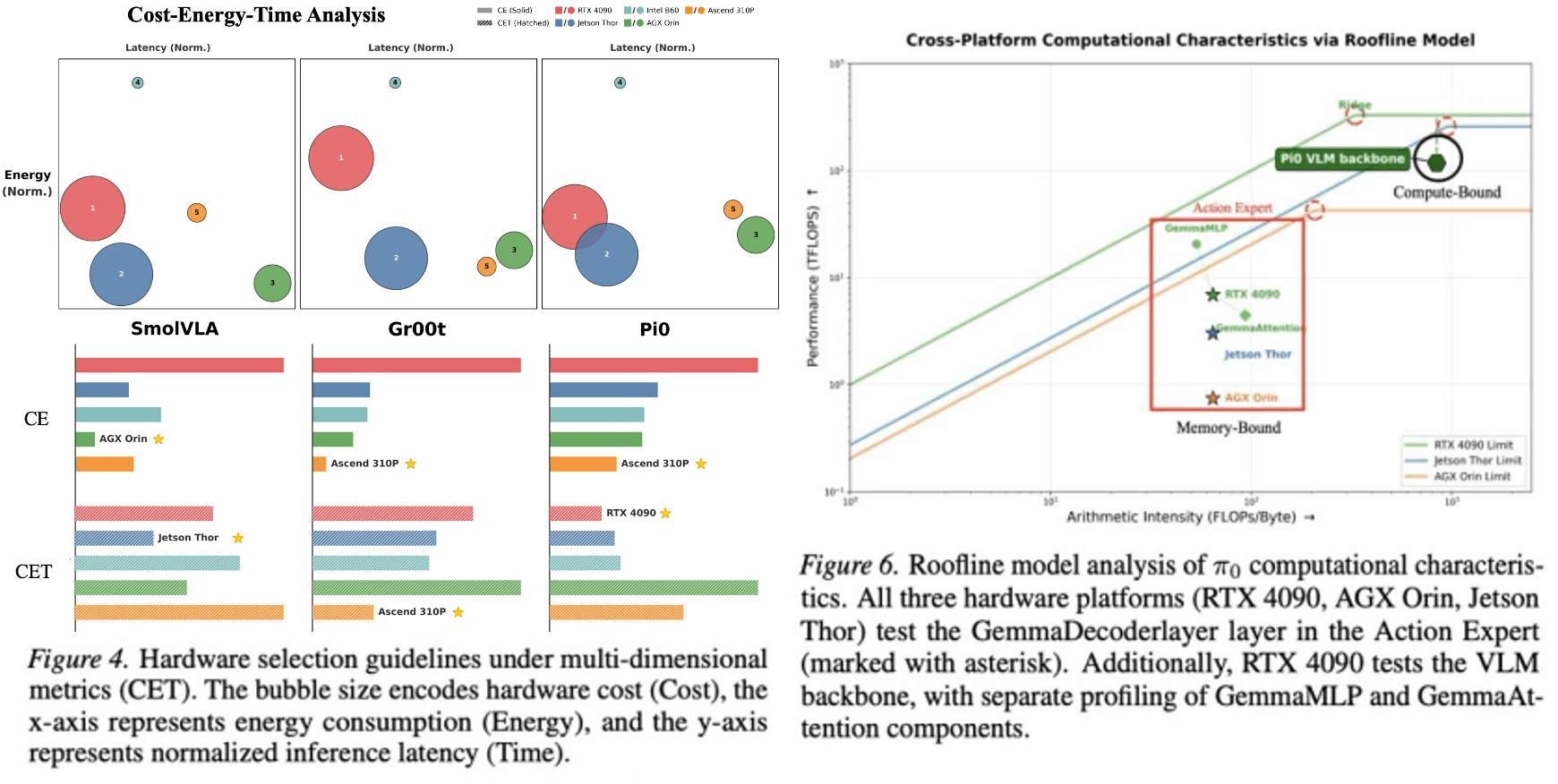
在性能分析方面,本工作通过细粒度Profiling分析,揭示主流VLA模型推理过程普遍呈现“两阶段”负载特征:前半部分VLM主干网络以计算密集型算子为主,后半部分Action Expert模块则更容易受到内存带宽限制。这种阶段性差异导致硬件资源利用不均衡,也为系统级优化提供了切入点。基于该观察,本论文提出两项训练无关的优化方法:DP-Cache利用扩散去噪过程中的冗余性,缓存稳定阶段的中间结果以减少重复计算;V-AEFusion利用机器人连续控制中相邻观测的时间相关性,将当前帧VLM计算与上一帧Action Expert早期去噪步骤进行异步流水重叠,从而隐藏关键路径上的VLM延迟。
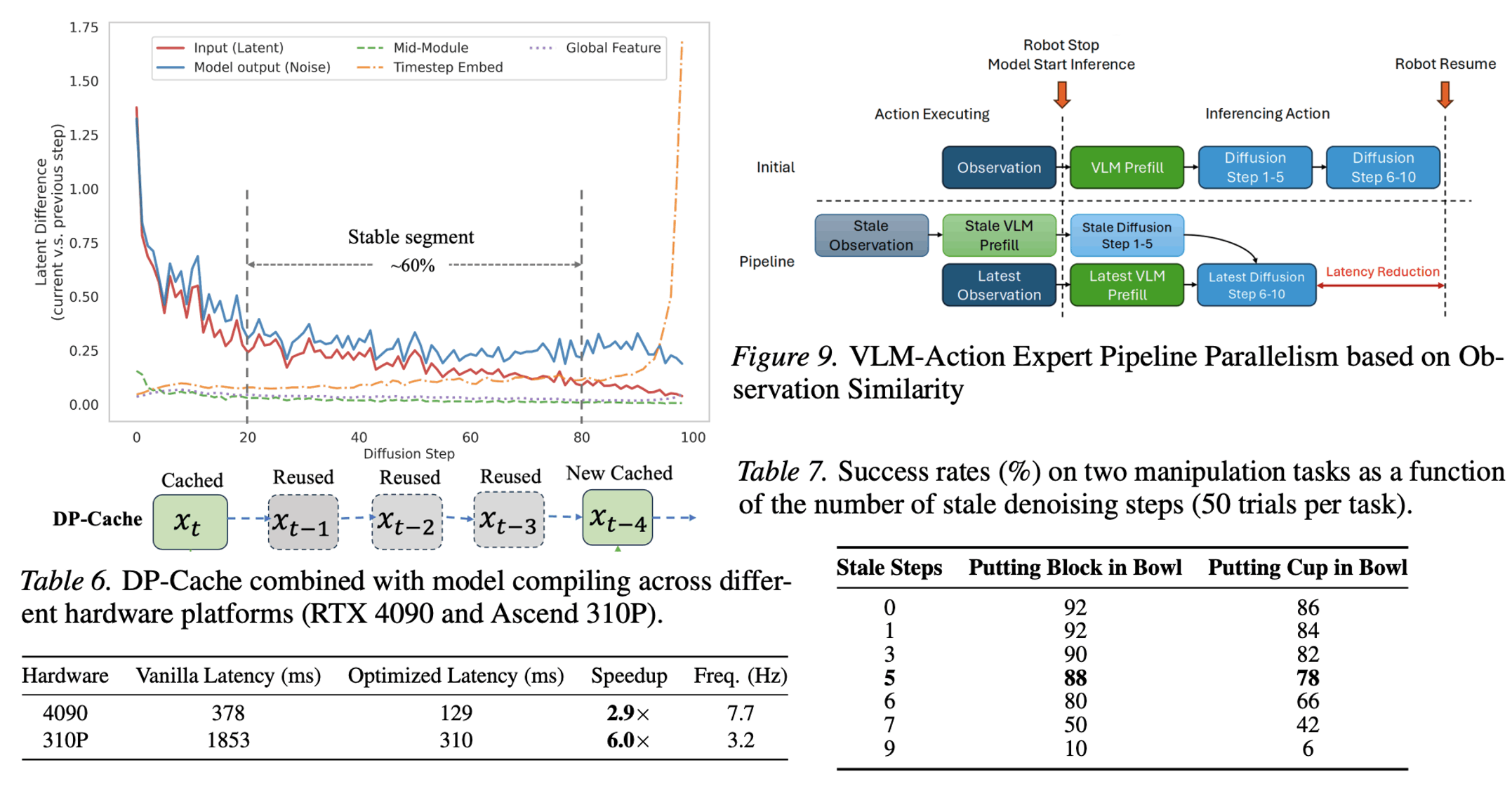
实验结果显示,该方法在华为端侧昇腾NPU设备上最高实现6倍加速。昇腾相关具身智能样例已开源至CANN社区(https://gitcode.com/cann/cann-recipes-embodied-intelligence),欢迎广大开发者体验和使用。
本论文成果为具身智能VLA模型在低成本、低能耗机器人平台上的端侧部署提供了系统化评测标准与高效加速路径。后续,开源鸿蒙具身智能PMC(筹)将继续围绕具身智能核心技术攻关与开源生态建设,推动VLA模型、异构硬件和机器人应用场景的协同演进,携手开发者与合作伙伴共建开源鸿蒙具身智能机器人生态。
论文信息
Kaijun Zhou, Qiwei Chen, Da Peng, Zhiyang Li, Xijun Li, Jinyu Gu. Characterizing Vision-Language-Action Models across XPUs: Constraints and Acceleration for On-Robot Deployment. International Conference on Machine Learning, 2026.

社区规范:仅讨论OpenHarmony相关问题。
更多推荐
 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)