【openHarmony第三方库】MMKV如何用文件锁与递归锁解决跨进程同步难题
暂时不支持直接存储自定义类,需要先将自定义类通过序列化为JSON数据,然后存储age: 23//存储序列化后的JSON信息//获得自定义类的JSON信息并反序列化处理。
1.什么是MMKV
mmkv是基于mmap内存映射的key-value组件,底层序列化反序列化使用protobuf实现,性能高,稳定性强,并且支持进程间并发读写
- mmap是由操作系统提供的一种内存管理技术,允许将一个文件直接映射到进程的虚拟地址空间中
- protobuf是由谷歌开发的一种结构化数据序列化机制,可以高效进行序列化和反序列化
2.MMKV原理
- 内存准备
- 通过mmap内存映射文件,提供一段可供随时写入的内存块,App负责向这个内存块里写数据,OS负责将内存写回到文件,这样解决了因为应用崩溃导致数据丢失的问题
- 数据序列化
- 数据序列化上使用protobuf协议
- 写入优化
- 增量更新:通过将对象序列化之后,直接写入内存映射区域的尾部,这样同一个key可能会对应多个value,然后在第一次打开mmkv时,不断用后读入的value替换前面的值,就可以保证数据最新,实现增量更新,相比传统定位到原数据后再修改,性能大幅提升
- 内存增长优化
- 每次以内存页的大小pageSize为单位申请空间,在空间用尽之前都是用append的模式添加数据,当添加到这个内存页的末尾时,会对文件进行重整,并重新保存重整结果;若重整后仍不够用则将文件大小扩大一倍,直到空间足够
- 数据有效性
- 使用CRC校验机制确保数据的完整性,若校验失败则拦截数据并上报云端,防止由于文件系统、操作不稳定引起的错误数据进入业务逻辑
3.基本操作
3.1获取实例
//获取全局默认实例
let kv: MMKV = MMKV.defaultMMKV();
//单独创建自己的MMKV实例,使用一个ID区分,可以根据业务逻辑区别存储
let kv_: MMKV = MMKV.mmkvWithID("MyID")>
3.2CURD操作
//增加/修改数据
kv.encodeBool(key_boolean,value);
kv.encodeInt32(key_Int32, value);
kv.encodeString(key_String, value);
...
//获得数据
let res = kv.decodeBool();
let res = kv.decodeInt64();
let res = kv.decodeString();
...
//删除数据
kv.removeValueForKey(key)//按照key值删除;
kv.removeValueForKeys([...key])//删除数组中所有key对应的value
如果需要多进程访问,需要在MMKV实例创建时进行额外配置
let kv = MMKV.mmkvWithID("MyID", MMKV.MULTI_PROCESS_MODE)
4.支持的数据类型
4.1原始类型
- boolean
- number
- bigint
- string
4.2引用类型
- Array[boolean]
- Array[number]
- Array[string]
- ArrayBuffer
- TypedArray:二进制数据类的数组对象的统称
4.3自定义类
暂时不支持直接存储自定义类,需要先将自定义类通过序列化为JSON数据,然后存储
let user = {
username: 'dummy_user',
age: 23
}
//存储序列化后的JSON信息
mmkv.encodeString('user', JSON.stringify(user))
//获得自定义类的JSON信息并反序列化处理
let jsonUser = mmkv.decodeString('user')
let userObject = JSON.parse(jsonUser)
5.进程间读写的同步
5.1状态同步
MMKV本质上是将文件mmap到内存块中,然后将新增的kv数据append到内存中,达到边界就进行重整,若重整之后空间还是不够就进行扩容;
在多进程环境中需要保证各个进程内数据的一致,需要解决三个问题:
- 各个进程间写指针的同步
- 如何获知当前内存是否被重整
- 如何获知当前内存是否被扩容
5.1.1写指针的同步
MMKV在每个进程内都缓存有自己的写指针,在每次写入时,也会将最新的写指针位置写入mmap内存中;每个进程在进行操作前只需要对比自身缓存的写指针值与mmap内存中的值是否相同,若不同,就需要将原指针与新指针之间的所有新键值都读出来,插入或替换原有的新键值,并将指针同步到新的为止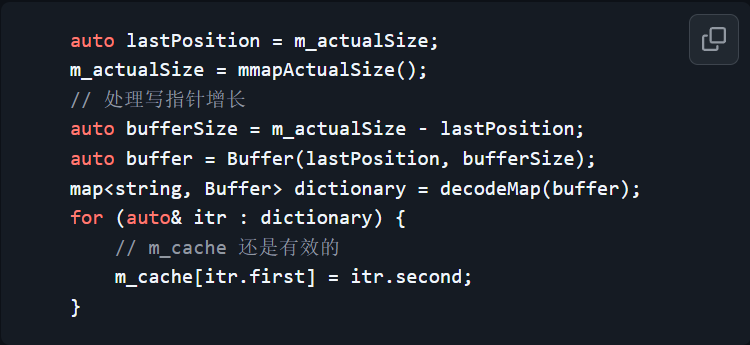
5.1.2内存重整
MMKV在每个进程内部也会缓存一个单调递增的序列号和当前进程记录的文件大小,当每次发生内存重整时,就将序列号递增,并将这个序列号也放到mmap内存中,每次操作前进行比较,若不一致再比较当前进程记录的文件大小与磁盘上的文件大小,如果相同则说明内存发生了重整,该进程就将原写指针前的数据全部抛弃,从头开始再加载一遍,不同则说明发生了内存扩容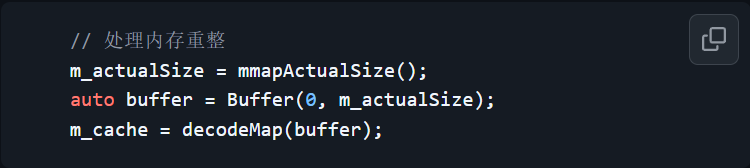
5.1.3内存扩容
因为在内存扩容之前会先进行内存重整,内存扩容的感知可以与内存重整一起处理,再判断序列号之后再判断当前进程记录的文件大小与实际文件大小,若发生内存扩容则同样把原写指针前的键值全部清除,从头再加载一遍
5.2文件锁
文件锁是一种进程间的同步机制,用于协调多个进程对同一个文件的并发访问。实际由操作系统内核实现,防止读写冲突,天然支持robust,即在进程崩溃时操作系统会自动回收文件描述符,释放锁
由于文件锁由操作系统底层提供,且不支持递归加锁和锁升级/降级,所以需要自己实现
- 递归锁
- 定义:如果一个进程、线程已经拥有了锁,那么后续的加锁操作不会导致卡死,而且解锁也不会导致外层的锁被解掉。
- 因为文件锁是状态锁,没有计数器,所以无论加了多少次锁都会被一次全部解掉
- 锁升级/降级
- 定义:锁升级是指将已经持有的共享锁,升级为互斥锁,也就是将读锁升级为写锁;锁降级也就是将写锁降级为读锁;
- 但是对文件锁来说A、B进程都持有读锁,想要升级到写锁就可能会陷入相互等待情况(进程AB同时申请写锁),发生死锁;而降级时,由于文件锁不支持递归锁,也导致锁降级无法进行
为了解决文件锁不支持递归锁和升降级操作的问题,需要对文件锁进行封装,加装读锁、写锁计数器,处理逻辑如下
- 实现递归锁:当只有读锁计数器有值或者写锁计数器有值时
- 加锁操作:给对应的锁计数器加一
- 解锁操作:给对应的锁计数器减一
实际在子函数中读写数据时,是不用加锁的,因为父函数中已经加过了,但是实际开发中,还要考虑函数复用和规范性问题,所以需要实现一个递归锁
- 实现锁升级:当读锁计数器的值不为0,写锁计数器值为0时
- 需要先解读锁,直到读锁计数器为1,也就是确保当前进程中的读者唯一,然后再进行解读锁,加写锁的操作
- 实现锁降级:当读锁的计数器为任意值,写锁计数器为1时
- 需要先加读锁,以确保在释放读锁后,底层文件锁的状态不会被释放,也就是在整个过程中文件始终有锁,没有间隙,变成了一个原子操作,最后再释放写锁
之所以在某一个计数器为0时执行特殊操作,是因为当计数器从0->1,或者从1->0时执行的是文件锁底层的加锁和解锁方法,其他情况可以直接对计数器进行操作

社区规范:仅讨论OpenHarmony相关问题。
更多推荐
 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)