基于OpenHarmony5.0.0\4.1的开发者手机TTS实现方案
一、什么是TTS TTS是Text-To-Speech的缩写,即“从文本到语音”。 它将计算机自己产生的、或外部输入的文字信息转变为可以听得懂的、流利的汉语口语(或者其他语言语音)输出的技术,隶属于语音合成(SpeechSynthesis)。 二、OpenHarmony如何实现TTS 本项目参考开源项目https:
一、什么是TTS
- TTS是Text-To-Speech的缩写,即“从文本到语音”。 它将计算机自己产生的、或外部输入的文字信息转变为可以听得懂的、流利的汉语口语(或者其他语言语音)输出的技术,隶属于语音合成(SpeechSynthesis)。
二、OpenHarmony如何实现TTS
-
本项目参考开源项目https://github.com/k2-fsa/sherpa-onnx实现。通过三方推理框架onnx运行时运行推理模型获取输出,最后在应用侧将模型输出在扬声器播放
sherpa-onnx 是由 Next-gen Kaldi 团队开发的一个开源项目,旨在提供高效的离线语音识别和语音合成解决方案。它支持多种平台,包括 Android、iOS、Raspberry Pi 等,能够在没有网络连接的情况下进行实时语音处理。该项目依赖于 ONNX Runtime 框架,提供从语音到文本(ASR)、文本到语音(TTS)以及语音活动检测(VAD)等功能,适用于各类嵌入式系统和移动设备。
-
源项目是基于HarmonyOS开发,OH4.1支持不友好,会闪退,所以笔者进行了兼容性适配,目前在开发者手机4.1/5.0都能运行。
项目流程图介绍
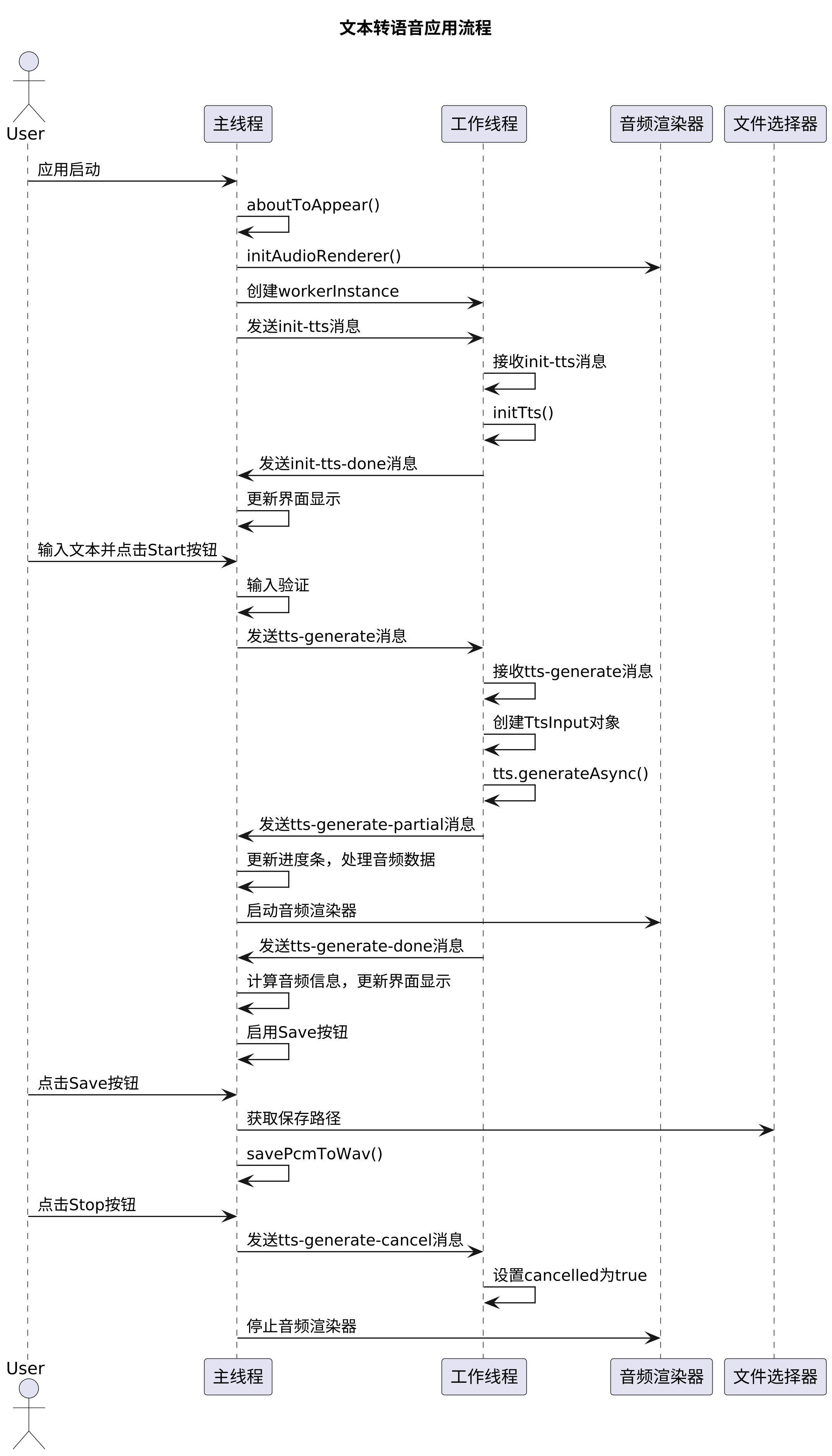
三、项目实操
3.1、环境准备
设备环境:开发者手机二代(版本:B710或B613)、开发者手机一代(B613)
开发环境:DevEco Studio 4.1 Release(构建版本:4.1.0.400)
SDK版本:4.1.9.2 Release full sdk
源码地址:https://gitee.com/MIKECODE/lavalphone_tts_demo.git
- 选用低版本DevEco和低版本SDK是为了构建兼容OH4.1的hap包
3.2、修改代码
首先使用git clone https://gitee.com/MIKECODE/lavalphone_tts_demo.git 获取代码并用DevEco4.1打开项目文件。
- 源项目缺少神经网络模型和签名。缺少签名无法安装,缺少神经网络模型会闪退。
3.2.1、获取神经网络模型
-
获取方式一:
- 直接从release版本(https://gitee.com/MIKECODE/lavalphone_tts_demo/releases/tag/release )中下载两个rar包并解压
- 解压后将hap包改后缀为zip,继续解压
- 复制\v1.0.0_com.laval.tts.zip\resources\rawfile\vits-melo-tts-zh_en文件夹到项目的rawfile目录
-
获取方式二:
- 从https://github.com/k2-fsa/sherpa-onnx/releases/download/tts-models/vits-melo-tts-zh/_en.tar.bz2 下载并解压
- 将vits-melo-tts-zh_en放到项目的的rawfile目录
文件目录为如下结构即设置完成
└───entry
└───src
└───main
├───ets
└───resources
├───base
├───en_US
│───zh_CN
└───rawfile
└───vits-melo-tts-zh_en //onnx神经网络模型文件
3.2.2、项目签名
- 打开项目结构(快捷键Ctrl+Alt+Shift+S)
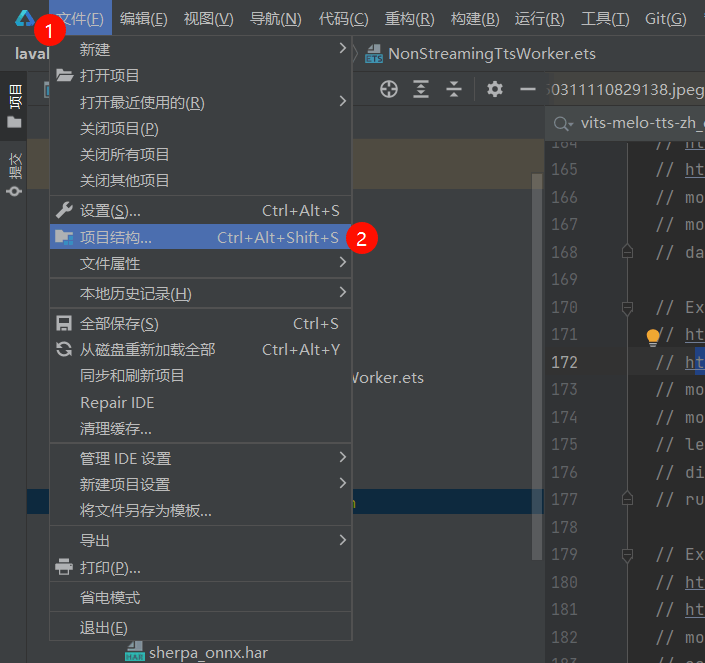
- 勾选自动签名并确定,等待同步完成
3.3、运行代码
- 确保以上步骤完成,用数据线连接设备和pc,点击run,应用即可安装至设备。
| 首页-模型加载中 | 首页-模型加载完成 | 首页-推理中 | 首页-推理完成 |
|---|---|---|---|
|
|
|
|
|

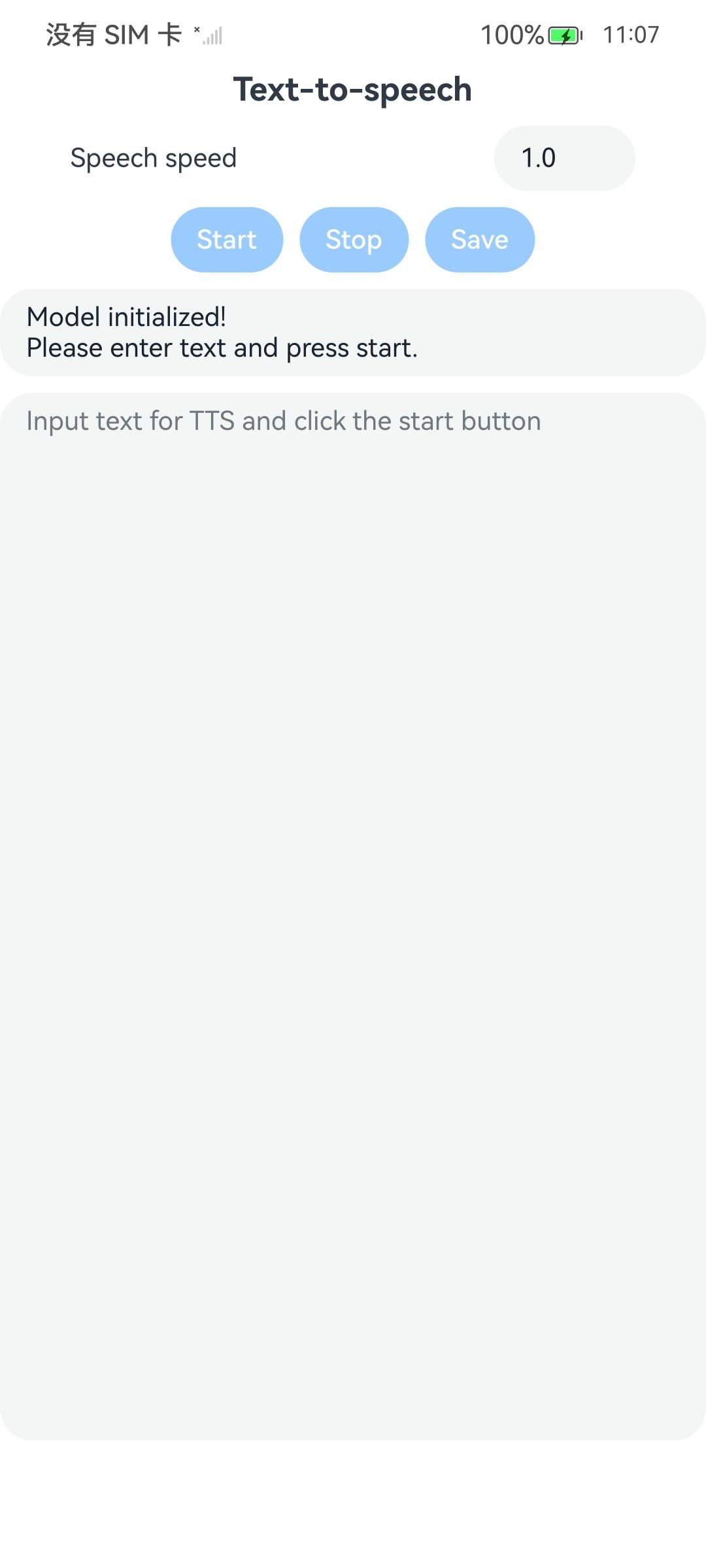

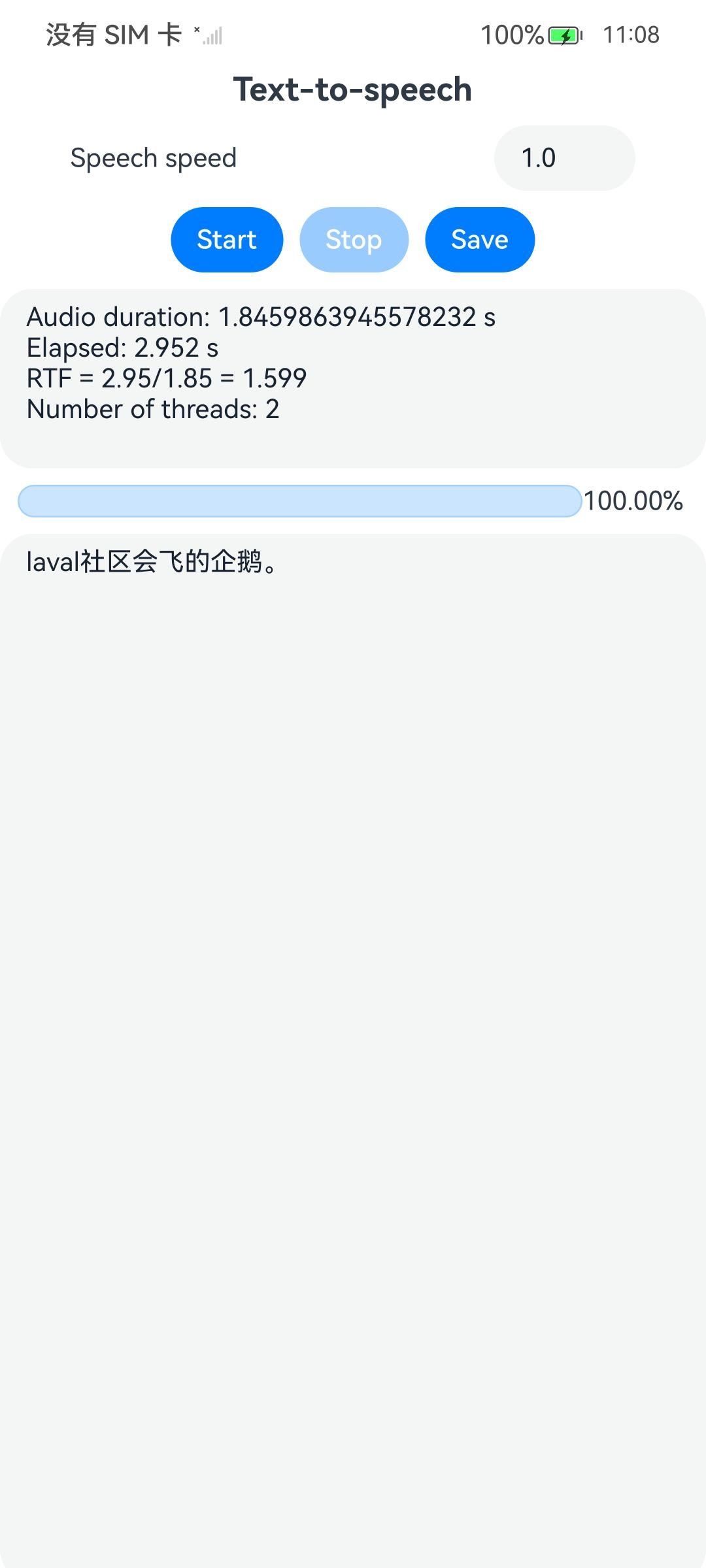
使用说明
- 首先打开应用,等待模型初始化。
- 文本框中输入需要转语音的文字,点击start,等待推理,推理完成后会自动播放结果并显示时间信息,至此完成一次文本转换,
- 若想持久化存储文件,可以在试听后点击Save按钮,选择保存路径为Download,文件保存为xxx.wav,实际路径在/storage/media/100/local/files/Docs/Download/xxx.wav。
- 可以使用hdc或者DevEco的图形化界面将文件传输到其他设备上。
四、自定义神经网络模型如何修改
-
下载支持的模型,支持的模型不止这些,原作者只列出了这些,可以自行尝试
// Example 1: // modelDir = 'vits-vctk'; // modelName = 'vits-vctk.onnx'; // lexicon = 'lexicon.txt'; // Example 2: // https://github.com/k2-fsa/sherpa-onnx/releases/tag/tts-models // https://github.com/k2-fsa/sherpa-onnx/releases/download/tts-models/vits-piper-en_US-amy-low.tar.bz2 // modelDir = 'vits-piper-en_US-amy-low'; // modelName = 'en_US-amy-low.onnx'; // dataDir = 'espeak-ng-data'; // Example 3: // https://github.com/k2-fsa/sherpa-onnx/releases/download/tts-models/vits-icefall-zh-aishell3.tar.bz2 // modelDir = 'vits-icefall-zh-aishell3'; // modelName = 'model.onnx'; // ruleFsts = 'phone.fst,date.fst,number.fst,new_heteronym.fst'; // ruleFars = 'rule.far'; // lexicon = 'lexicon.txt'; // Example 4: // https://k2-fsa.github.io/sherpa/onnx/tts/pretrained_models/vits.html#csukuangfj-vits-zh-hf-fanchen-c-chinese-187-speakers // modelDir = 'vits-zh-hf-fanchen-C'; // modelName = 'vits-zh-hf-fanchen-C.onnx'; // lexicon = 'lexicon.txt'; // dictDir = 'dict'; // Example 5: // https://github.com/k2-fsa/sherpa-onnx/releases/download/tts-models/vits-coqui-de-css10.tar.bz2 // modelDir = 'vits-coqui-de-css10'; // modelName = 'model.onnx'; // Example 6 // https://github.com/k2-fsa/sherpa-onnx/releases/tag/tts-models // https://github.com/k2-fsa/sherpa-onnx/releases/download/tts-models/vits-piper-en_US-libritts_r-medium.tar.bz2 // modelDir = 'vits-piper-en_US-libritts_r-medium'; // modelName = 'en_US-libritts_r-medium.onnx'; // dataDir = 'espeak-ng-data'; // Example 7 // https://github.com/k2-fsa/sherpa-onnx/releases/tag/tts-models // https://github.com/k2-fsa/sherpa-onnx/releases/download/tts-models/vits-melo-tts-zh_en.tar.bz2 // modelDir = 'vits-melo-tts-zh_en'; // modelName = 'model.onnx'; // lexicon = 'lexicon.txt'; // dictDir = 'dict'; // ruleFsts = `date.fst,phone.fst,number.fst`; // Example 8 // https://github.com/k2-fsa/sherpa-onnx/releases/tag/tts-models // https://k2-fsa.github.io/sherpa/onnx/tts/pretrained_models/matcha.html#matcha-icefall-zh-baker-chinese-1-female-speaker // modelDir = 'matcha-icefall-zh-baker'; // acousticModelName = 'model-steps-3.onnx'; // vocoder = 'hifigan_v2.onnx'; // lexicon = 'lexicon.txt'; // dictDir = 'dict'; // ruleFsts = `date.fst,phone.fst,number.fst`; // Example 9 // https://github.com/k2-fsa/sherpa-onnx/releases/tag/tts-models // https://k2-fsa.github.io/sherpa/onnx/tts/pretrained_models/matcha.html#matcha-icefall-en-us-ljspeech-american-english-1-female-speaker // modelDir = 'matcha-icefall-en_US-ljspeech'; // acousticModelName = 'model-steps-3.onnx'; // vocoder = 'hifigan_v2.onnx'; // dataDir = 'espeak-ng-data'; // Example 10 // https://k2-fsa.github.io/sherpa/onnx/tts/pretrained_models/kokoro.html#kokoro-en-v0-19-english-11-speakers // modelDir = 'kokoro-en-v0_19'; // modelName = 'model.onnx'; // voices = 'voices.bin' // dataDir = 'espeak-ng-data'; -
将下载的模型解压移动至项目的的rawfile目录
-
修改NonStreamingTtsWorker.ets的207行左右。将模型下载链接处的参数修改至下面红框部分
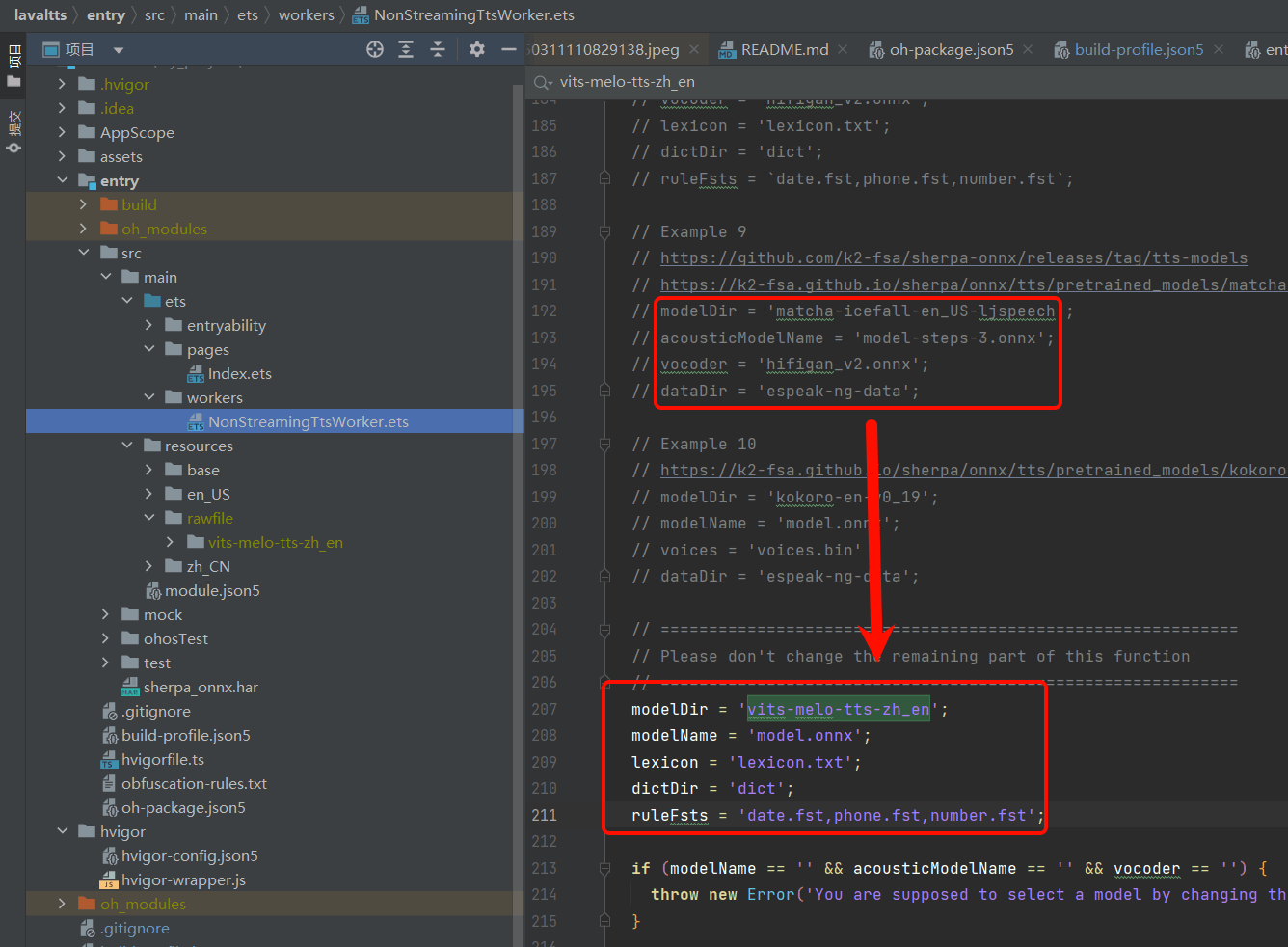
-
对应修改NonStreamingTtsWorker.ets的copyRawFileDirToSandbox方法模型名。原操作为Native接口操作rawfile文件夹,但部分接口OH4.1没有,所以转移到ts侧进行操作。
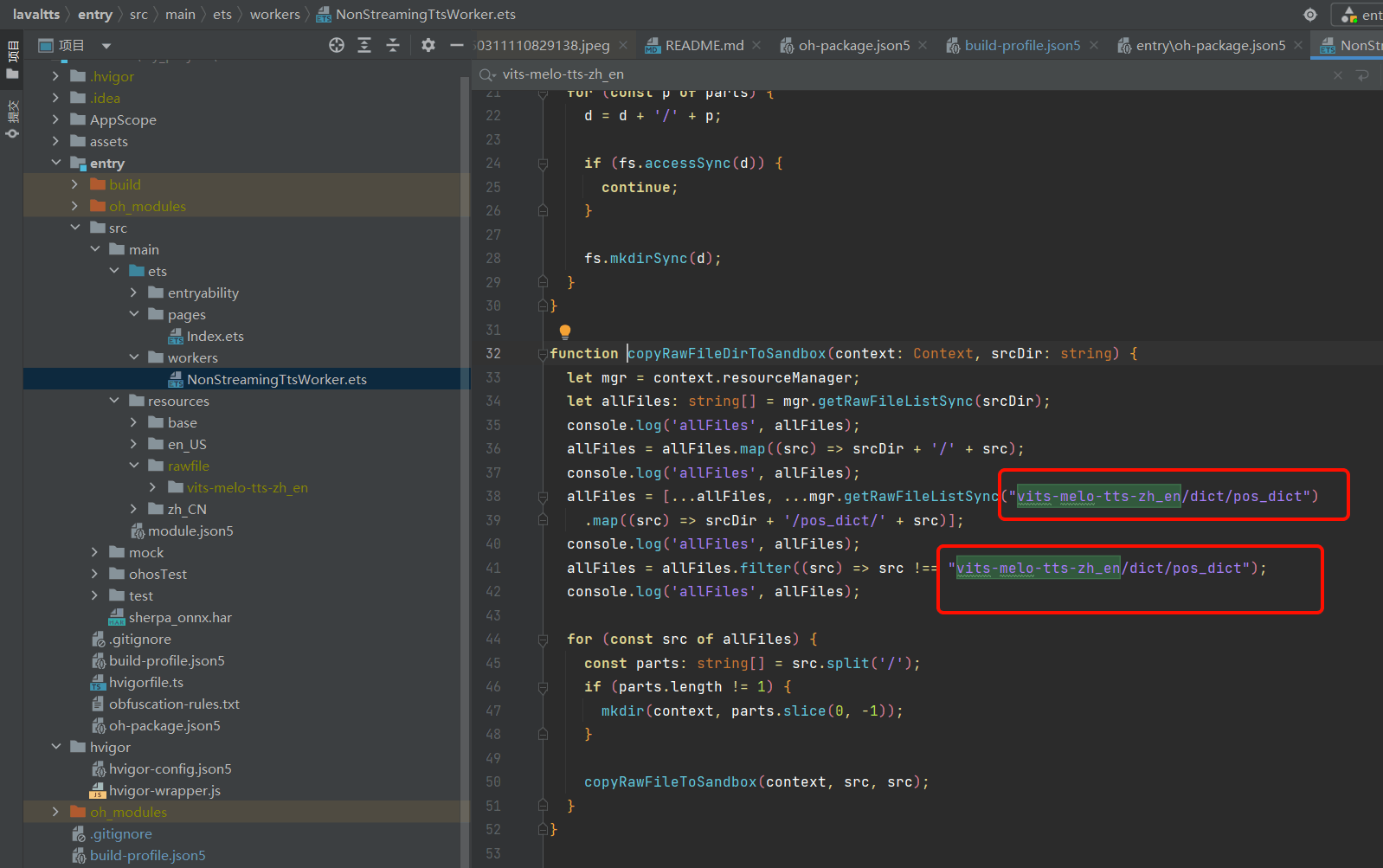
-
确保以上步骤完成,用数据线连接设备和pc,点击run,应用即可安装至设备。
五、其他
本项目开源地址:https://gitee.com/MIKECODE/lavalphone_tts_demo
本项目release版本已经上传开发者手机分发中心,可以直接下载体验。

社区规范:仅讨论OpenHarmony相关问题。
更多推荐
 6
6 2
2- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)