图形子系统关键技术赋能——Skia框架
Skia
整体
Skia是干什么的
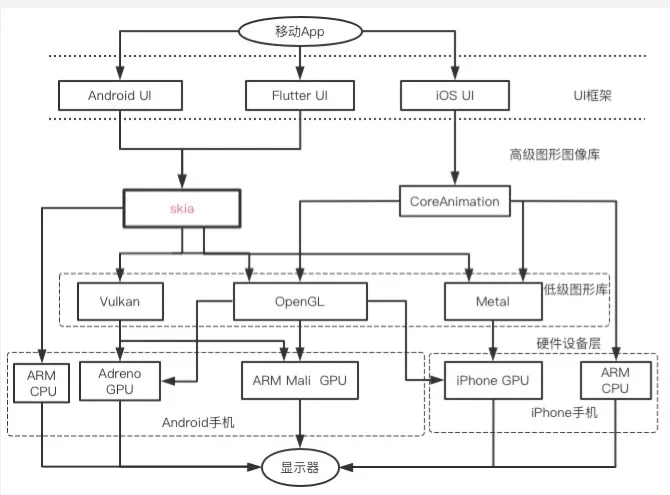
Skia是一个功能强大的跨平台图形库,不仅提供了图形渲染功能,还提供文字绘制和图片显示功能。高级图形图像库将需要绘制的图形转成点、线、三角形等图元,再调用底层图形接口实现绘制。能绘制矩形、圆形、曲线等矢量图,绘制点阵字体和矢量字体,显示jpeg、png、gif、webp等图片,从算法和硬件两个层面进行了优化所以性能好。
Skia框架分析
1.Skia外部组件依赖
Skia依赖的第三方库众多,包括字体解析库freeType,图片编解码库libjpeg-turbo、libpng、libgifocode、libwebp和pdf文档处理库fpdfemb等。Skia支持多种软硬件平台,既支持ARM和x86指令集,也支持OpenGL、Metal和Vulkan低级图形接口。
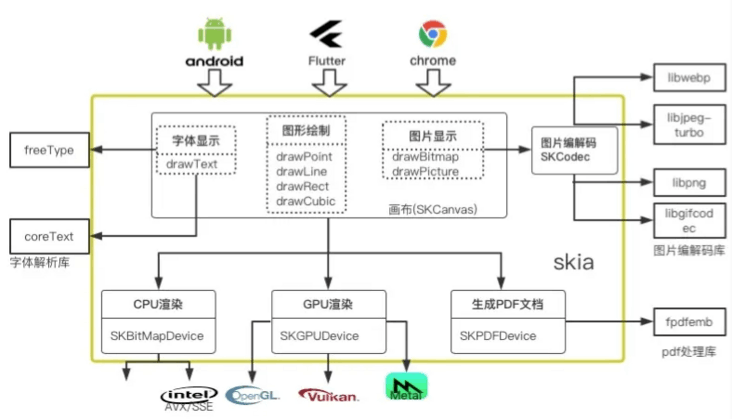
2.Skia 层次分析
Skia在结构上大致分成三层:画布层,渲染设备层和封装适配层。
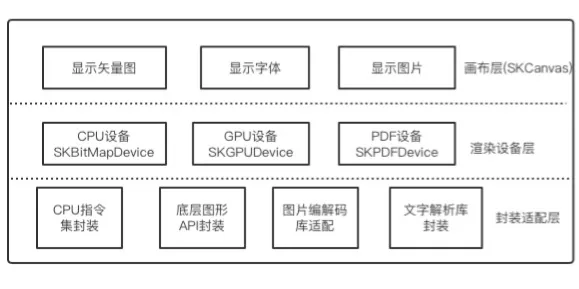
2.1 画布层
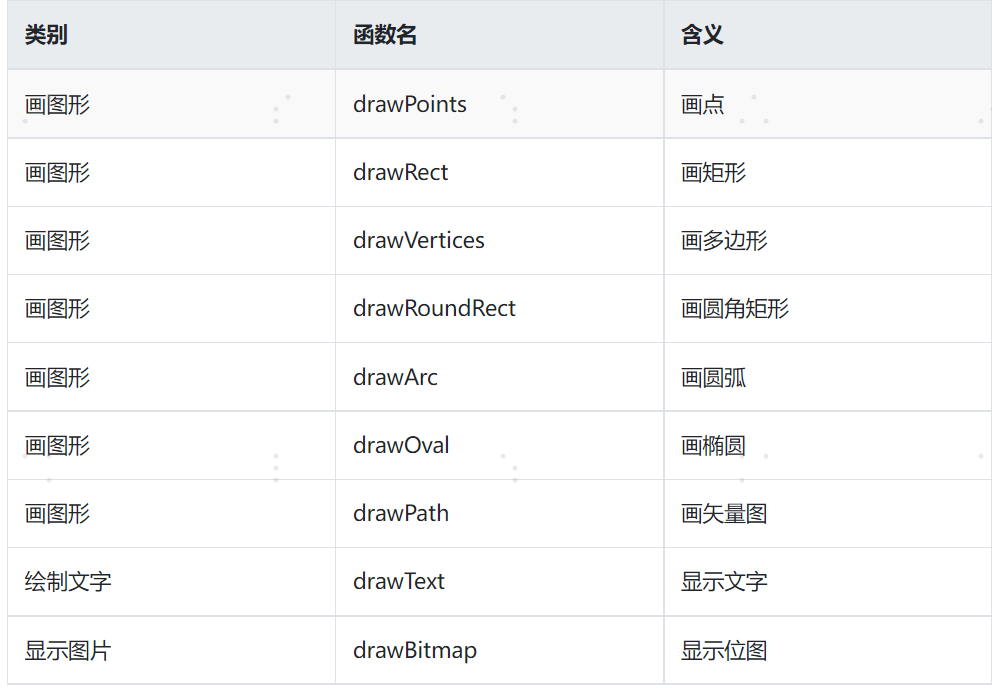
画布层可以理解成提供给开发者在一个设备无关的画布,可以在上面绘制各种图形,且不用关心硬件细节,功能如下:
2.2 渲染设备层
渲染设备层负责画布层的硬件实现,skia将设备封装成下面三个类:
SKBitmapDevice
CPU渲染模式绘图,用于没有显卡或者显卡驱动的设备。此模式下,最后会将需要绘制的图形转成位图数据(RGB)写入指定内存,故称为BitmapDevice。写内存操作通过AVX或者NEON指令集实现。
SKGPUDevice
GPU渲染方式绘图。目前大部分移动设备和个人电脑都有GPU,GPU比CPU的运算单元多,并行计算能力强,通过GPU绘图可降低CPU占用,性能更好。
SKPDFDevice
选用此设备时,渲染结果不是输出到显示器的画面,而是输出为pdf文件。
可以通过skia官网在线体验不同设备的渲染结果:https://fiddle.skia.org/c/@sh@sh...
2.3封装适配层
Skia为了屏蔽不同依赖库的接口差异,对依赖库进行了封装和适配。例如基于图片编解码库libjpeg-turbo、libpng、libwebp 封装了类SKJpegCodec、SKPngCodec、SKWebpCodec。基于底层图形库OpenGL、Metal、Vulkan封装了GrGLOpsRenderPass, GrMTOpsRenderPass, GrVKOpsRenderPass三个类。
3.Skia中图形GPU渲染
GPU的并行运算能力强,目前大部分移动设备都采用的是GPU渲染。
skia GPU渲染流程如下:
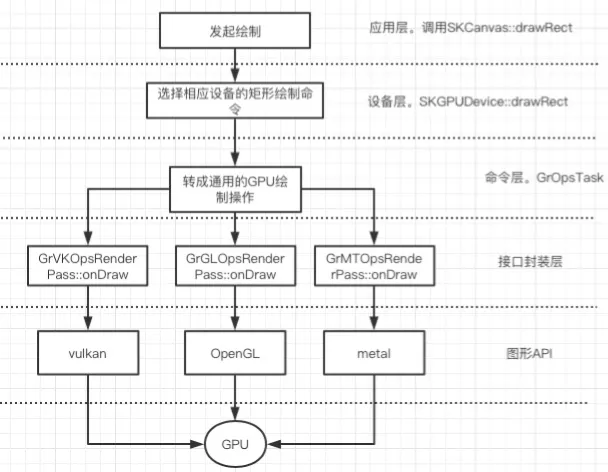
1)发起绘图,先调用SKCanvas的绘图函数drawRect,传入左上角和右下角顶点坐标。
2)调用GPU设备的绘图函数SKGPUDevice::drawRect。
3)采用命令模式,将GPU绘图操作封装成类GrOpsTask的实例。
4)根据软硬件平台的不同选用不同的底层API。
OpenGL(Open Graphics Library”)是目前使用最广泛的跨平台图形变成接口,跨平台特性好,大部分操作系统和GPU。Skia在大部分平台采用OpenGL实现GPU绘图,少部分平台调用Metal和vulkan。
Metal是苹果公司2014年推出的和 OpenGL类似的面向底层的图形编程接口,只支持iOS。对软硬件有要求,要求硬件苹果A7及以后,操作系统iOS 10及以上。Metal理论上性能比OpenGL性能强,故新设备中开启Metal可提高性能。例如Flutter中已启用了metal支持,详情参考https://github.com/flutter/fl...%E3%80%82
Vulkan是新一代跨平台的2D和3D绘图应用程序接口(API),旨在取代OpenGL,理论上性能强于OpenGL。自 Android 7.0 开发者预览版开始,Google便在系统平台中添加了对Vulkan的API支持。目前Skia的GPU渲染模式已用vulkan实现了一套,但存在一些bug。具体参考https://skia.org/user/special...%E3%80%82
Skia对上述三种图形接口进行了封装,屏蔽了不同底层图形API接口的差异。OpenGL接口的封为GrGLOpsRenderPass,Metal的封装层为GrMTOpsRenderPass,Vuklan的封装层为 GrVKOpsRenderPass。
drwaRect()是怎么使用Skia能力的
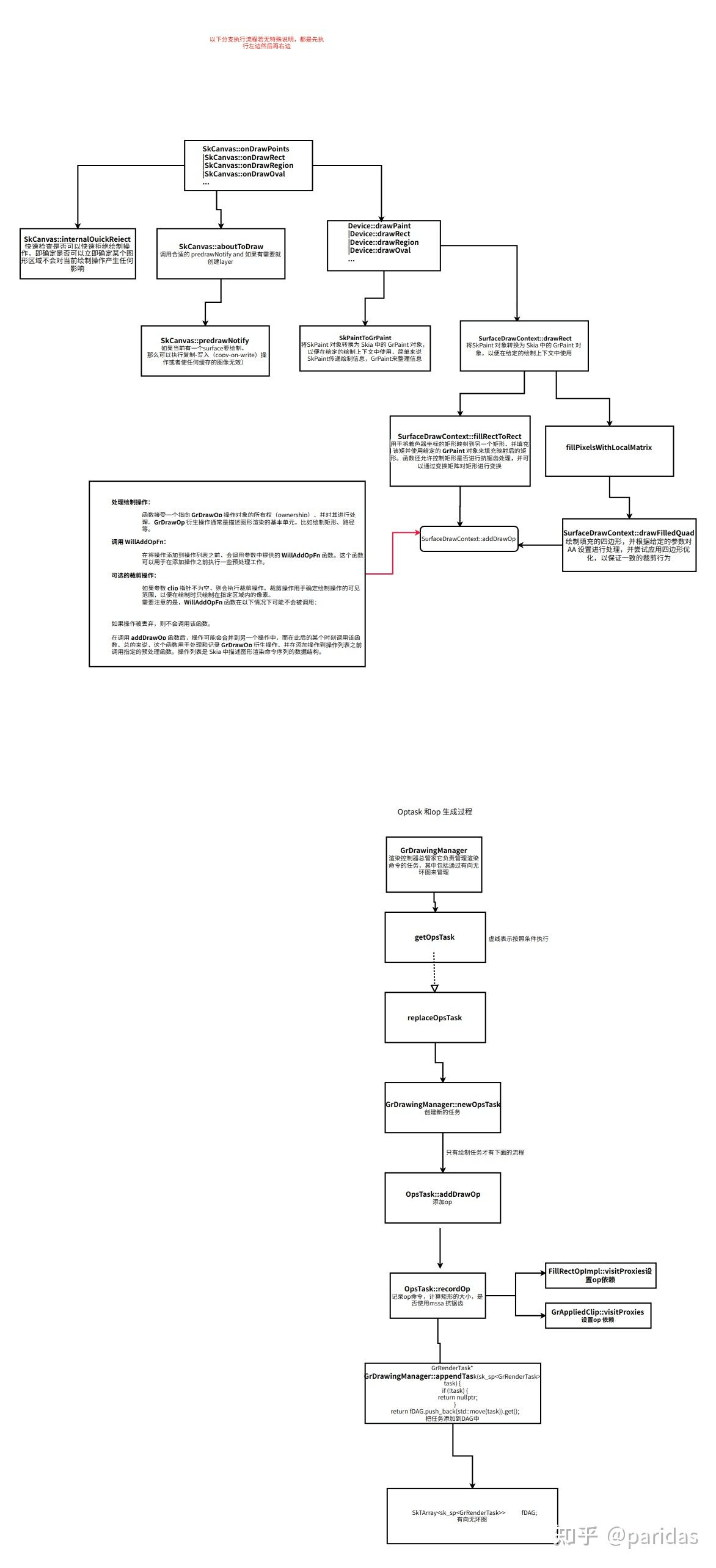
1. SkCanvas::drawRect
void SkCanvas::drawRect(const SkRect& r, const SkPaint& paint) {
TRACE_EVENT0("skia", TRACE_FUNC);
// To avoid redundant logic in our culling code and various backends, we always sort rects
// before passing them along.
this->onDrawRect(r.makeSorted(), paint);
}
void SkCanvas::onDrawRect(const SkRect& r, const SkPaint& paint) {
// 确保矩形的边界是正确排序的,如果未排序,则断言失败
SkASSERT(r.isSorted());
// 如果快速拒绝判定矩形不需要绘制(例如超出可见范围),直接返回
if (this->internalQuickReject(r, paint)) {
return;
}
// 准备绘制上下文,处理图层或其他绘制前的必要信息
auto layer = this->aboutToDraw(this, paint, &r, CheckForOverwrite::kYes);
// 如果返回有效图层,则调用顶层设备进行矩形的实际绘制
if (layer) {
this->topDevice()->drawRect(r, layer->paint());
}
}
2.选择使用GPU设备
void Device::drawRect(const SkRect& rect, const SkPaint& paint) {
ASSERT_SINGLE_OWNER
GR_CREATE_TRACE_MARKER_CONTEXT("skgpu::v1::Device", "drawRect", fContext.get());
// 将 SkPaint 转换为 GrStyle,表示绘制的样式
GrStyle style(paint);
// 如果 SkPaint 包含 MaskFilter 或 PathEffect,需要通过 drawPath 处理
if (paint.getMaskFilter() || paint.getPathEffect()) {
GrStyledShape shape(rect, style);
// 使用 GrBlurUtils 绘制带有 MaskFilter 效果的形状
GrBlurUtils::drawShapeWithMaskFilter(fContext.get(), fSurfaceDrawContext.get(),
this->clip(), paint, this->asMatrixProvider(), shape);
return;
}
// 创建一个 GrPaint 对象,用于存储 GPU 渲染所需的状态
GrPaint grPaint;
// 将 SkPaint 转换为 GrPaint,若转换失败,则退出
if (!SkPaintToGrPaint(this->recordingContext(), fSurfaceDrawContext->colorInfo(), paint,
this->asMatrixProvider(), &grPaint)) {
return;
}
// 最终通过 fSurfaceDrawContext 绘制矩形,传入抗锯齿设置和其他必要参数
fSurfaceDrawContext->drawRect(this->clip(), std::move(grPaint),
fSurfaceDrawContext->chooseAA(paint), this->localToDevice(), rect,
&style);
}
3.绘制命令生成 op 指令加入到 opstask 中
void SurfaceDrawContext::drawRect(const GrClip* clip,
GrPaint&& paint,
GrAA aa,
const SkMatrix& viewMatrix,
const SkRect& rect,
const GrStyle* style) {
// 如果未传入 style,则使用默认的简单填充样式
if (!style) {
style = &GrStyle::SimpleFill();
}
ASSERT_SINGLE_OWNER
// 检查当前绘制上下文是否已经被放弃
RETURN_IF_ABANDONED
SkDEBUGCODE(this->validate();)
GR_CREATE_TRACE_MARKER_CONTEXT("SurfaceDrawContext", "drawRect", fContext);
// 确保路径效果已经在上游处理过,当前不再处理
SkASSERT(!style->pathEffect());
// 自动检查绘制刷新
AutoCheckFlush acf(this->drawingManager());
// 获取样式中的描边信息
const SkStrokeRec& stroke = style->strokeRec();
// 如果样式是填充,直接调用 fillRectToRect 进行矩形填充
if (stroke.getStyle() == SkStrokeRec::kFill_Style) {
this->fillRectToRect(clip, std::move(paint), aa, viewMatrix, rect, rect);
return;
}
// 如果样式是描边或发散描边,且矩形非空且支持抗锯齿
else if ((stroke.getStyle() == SkStrokeRec::kStroke_Style ||
stroke.getStyle() == SkStrokeRec::kHairline_Style) &&
rect.width() &&
rect.height() &&
!this->caps()->reducedShaderMode()) {
// 对非空矩形使用 StrokeRectOp 进行描边操作,避免空矩形引起的问题
// 根据条件选择抗锯齿类型(MSAA)
GrAAType aaType = (fCanUseDynamicMSAA &&
stroke.getJoin() == SkPaint::kMiter_Join &&
stroke.getMiter() >= SK_ScalarSqrt2) ? GrAAType::kCoverage
: this->chooseAAType(aa);
GrOp::Owner op = StrokeRectOp::Make(fContext, std::move(paint), aaType, viewMatrix,
rect, stroke);
// 如果创建了有效的op操作指令,则将其添加到绘制队列中
if (op) {
this->addDrawOp(clip, std::move(op));
return;
}
}
// 确保 paint 对象有效
assert_alive(paint);
// 如果以上条件都不满足,则使用路径渲染器进行绘制
this->drawShapeUsingPathRenderer(clip, std::move(paint), aa, viewMatrix,
GrStyledShape(rect, *style, DoSimplify::kNo));
}
Skia怎么执行OP( 渲染)指令的
1.rsmain调用 FlushAndSubmit
void RSMainThread::ClearMemoryCache(ClearMemoryMoment moment, bool deeply, pid_t pid)
{
...
grContext->FlushAndSubmit(true);
this->clearMemoryFinished_ = true;
this->exitedPidSet_.clear();
this->clearMemDeeply_ = false;
this->SetClearMoment(ClearMemoryMoment::NO_CLEAR);
...
}
2. 选择GPU设备 SkiaGPUContext
void SkiaGPUContext::FlushAndSubmit(bool syncCpu)
{
if (!grContext_) {
LOGD("SkiaGPUContext::FlushAndSubmit, grContext_ is nullptr");
return;
}
grContext_->flushAndSubmit(syncCpu);
}
3. GrOpsTask 开始执行OP指令
// MDB TODO: make use of the 'proxies' parameter.
bool GrDrawingManager::flush(
...
bool flushed = !resourceAllocator.failedInstantiation() &&
this->executeRenderTasks(&flushState);
this->removeRenderTasks();
gpu->executeFlushInfo(proxies, access, info, newState);
...
return true;
}
bool GrDrawingManager::executeRenderTasks(GrOpFlushState* flushState) {
...
// Execute the onFlush renderTasks first, if any.
for (sk_sp<GrRenderTask>& onFlushRenderTask : fOnFlushRenderTasks) {
if (!onFlushRenderTask->execute(flushState)) {
SkDebugf("WARNING: onFlushRenderTask failed to execute.\n");
}
SkASSERT(onFlushRenderTask->unique());
onFlushRenderTask->disown(this);
onFlushRenderTask = nullptr;
if (++numRenderTasksExecuted >= kMaxRenderTasksBeforeFlush) {
flushState->gpu()->submitToGpu(false);
numRenderTasksExecuted = 0;
}
}
fOnFlushRenderTasks.reset();
...
}
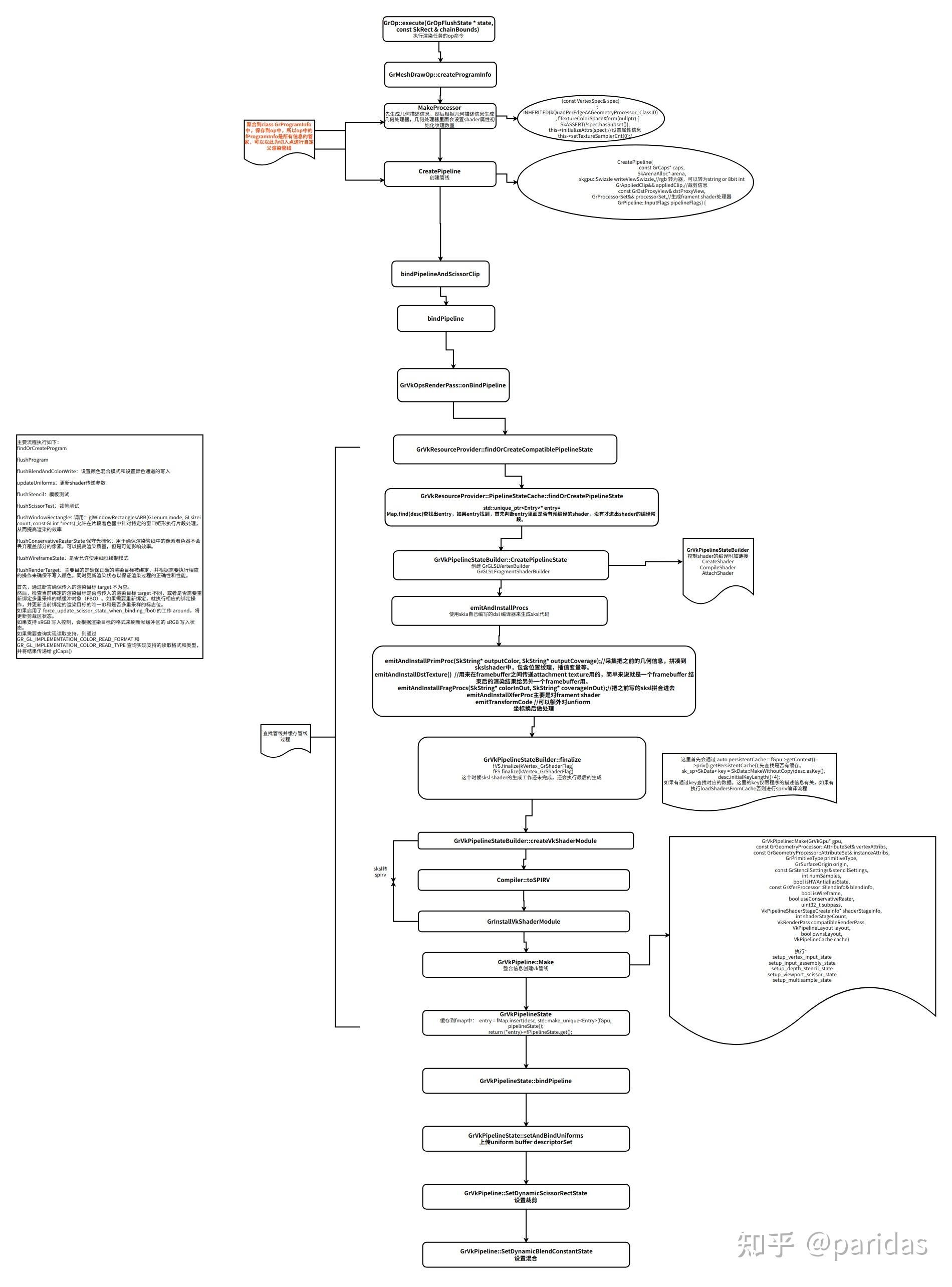
4.任务准备阶段
5.运行OpsTask,创建Renderpass,收集信息
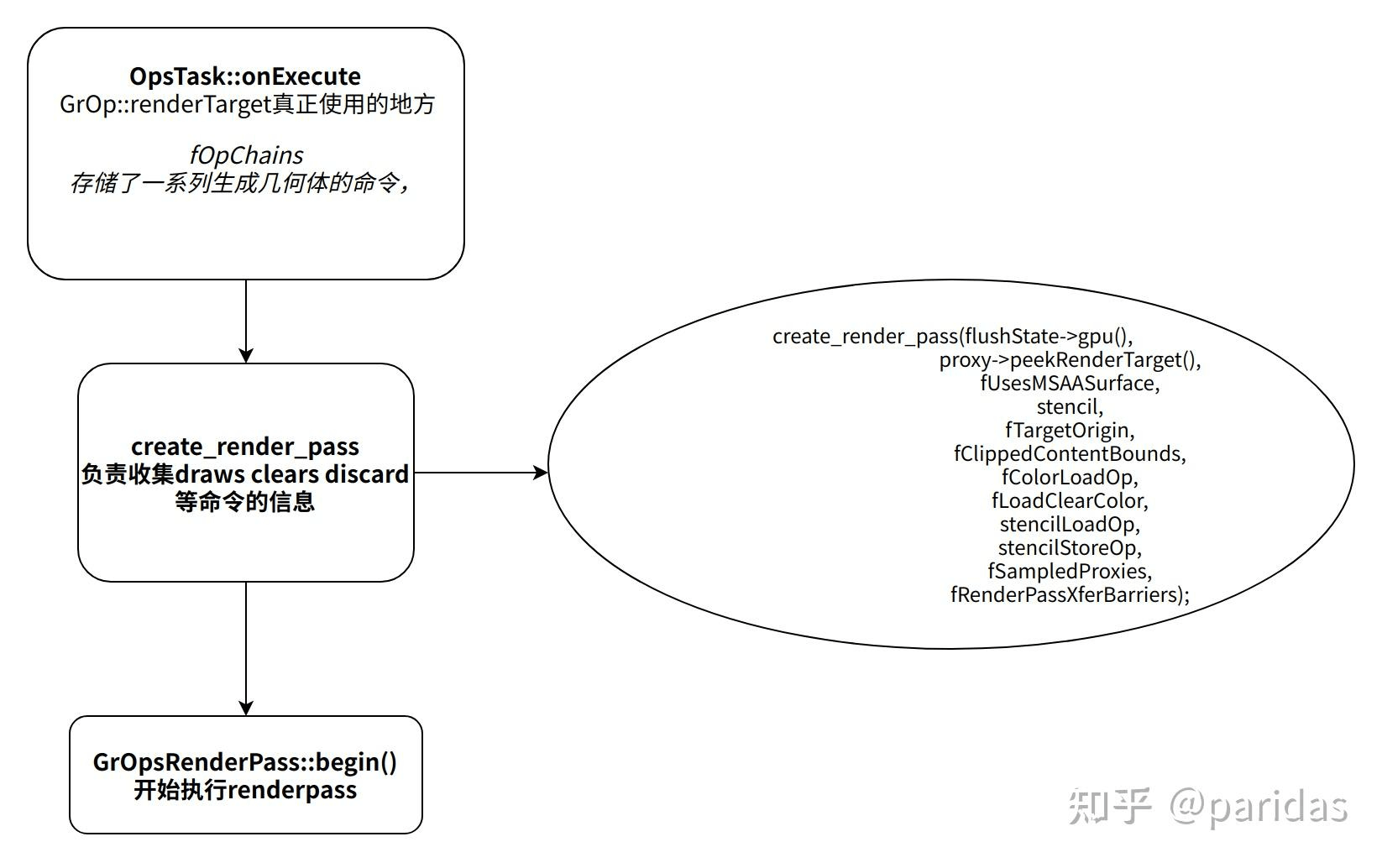
bool OpsTask::onExecute(GrOpFlushState* flushState) {
...
// NOTE: If fMustPreserveStencil is set, then we are executing a surfaceDrawContext that split
// its opsTask.
//
// FIXME: We don't currently flag render passes that don't use stencil at all. In that case
// their store op might be "discard", and we currently make the assumption that a discard will
// not invalidate what's already in main memory. This is probably ok for now, but certainly
// something we want to address soon.
GrStoreOp stencilStoreOp = (caps.discardStencilValuesAfterRenderPass() && !fMustPreserveStencil)
? GrStoreOp::kDiscard
: GrStoreOp::kStore;
GrOpsRenderPass* renderPass = create_render_pass(flushState->gpu(),
proxy->peekRenderTarget(),
fUsesMSAASurface,
stencil,
fTargetOrigin,
fClippedContentBounds,
fColorLoadOp,
fLoadClearColor,
stencilLoadOp,
stencilStoreOp,
fSampledProxies,
fRenderPassXferBarriers);
if (!renderPass) {
return false;
}
flushState->setOpsRenderPass(renderPass);
renderPass->begin();
GrSurfaceProxyView dstView(sk_ref_sp(this->target(0)), fTargetOrigin, fTargetSwizzle);
auto grGpu = flushState->gpu();
// Draw all the generated geometry.
GrGpuResourceTag tag;
for (const auto& chain : fOpChains) {
if (!chain.shouldExecute()) {
continue;
}
#ifdef SK_BUILD_FOR_ANDROID_FRAMEWORK
TRACE_EVENT0("skia.gpu", chain.head()->name());
#endif
tag = chain.head()->getGrOpTag();
if (grGpu && tag.isGrTagValid()) {
grGpu->setCurrentGrResourceTag(tag);
}
GrOpFlushState::OpArgs opArgs(chain.head(),
dstView,
fUsesMSAASurface,
chain.appliedClip(),
chain.dstProxyView(),
fRenderPassXferBarriers,
fColorLoadOp);
flushState->setOpArgs(&opArgs);
chain.head()->execute(flushState, chain.bounds());
flushState->setOpArgs(nullptr);
if (grGpu && tag.isGrTagValid()) {
grGpu->popGrResourceTag();
}
}
renderPass->end();
flushState->gpu()->submit(renderPass);
flushState->setOpsRenderPass(nullptr);
return true;
}
6.execute主要包括四大阶段 管线生成绑定,必要时进行裁剪; 绑定各种buffer, 绑定图片; 调用绘制api执行绘制
void onExecute(GrOpFlushState* flushState, const SkRect& chainBounds) override {
if (!fVertexBuffer) {
return;
}
const VertexSpec vertexSpec = this->vertexSpec();
if (vertexSpec.needsIndexBuffer() && !fIndexBuffer) {
return;
}
if (!fProgramInfo) {
this->createProgramInfo(flushState);
}
const int totalNumVertices = fQuads.count() * vertexSpec.verticesPerQuad();
flushState->bindPipelineAndScissorClip(*fProgramInfo, chainBounds);
flushState->bindBuffers(std::move(fIndexBuffer), nullptr, std::move(fVertexBuffer));
flushState->bindTextures(fProgramInfo->geomProc(), nullptr, fProgramInfo->pipeline());
skgpu::v1::QuadPerEdgeAA::IssueDraw(flushState->caps(), flushState->opsRenderPass(),
vertexSpec, 0, fQuads.count(), totalNumVertices,
fBaseVertex);
}
7.管线阶段:生成shader 绑定管线
void GrMeshDrawOp::createProgramInfo(GrMeshDrawTarget* target) {
this->createProgramInfo(&target->caps(),
target->allocator(),
target->writeView(),
target->usesMSAASurface(),
target->detachAppliedClip(),
target->dstProxyView(),
target->renderPassBarriers(),
target->colorLoadOp());
}
void onCreateProgramInfo(const GrCaps* caps,
SkArenaAlloc* arena,
const GrSurfaceProxyView& writeView,
bool usesMSAASurface,
GrAppliedClip&& appliedClip,
const GrDstProxyView& dstProxyView,
GrXferBarrierFlags renderPassXferBarriers,
GrLoadOp colorLoadOp) override {
const VertexSpec vertexSpec = this->vertexSpec();
//MakeProcessor 生成几何描述信息,根据集合描述信息生成几何处理器,几何处理器里会设置 shader 属性初始化纹理数量
GrGeometryProcessor* gp = skgpu::v1::QuadPerEdgeAA::MakeProcessor(arena, vertexSpec);
SkASSERT(gp->vertexStride() == vertexSpec.vertexSize());
fProgramInfo = fHelper.createProgramInfoWithStencil(caps, arena, writeView, usesMSAASurface,
std::move(appliedClip),
dstProxyView, gp,
vertexSpec.primitiveType(),
renderPassXferBarriers, colorLoadOp);
}
GrProgramInfo* GrSimpleMeshDrawOpHelperWithStencil::createProgramInfoWithStencil(
const GrCaps* caps,
SkArenaAlloc* arena,
const GrSurfaceProxyView& writeView,
bool usesMSAASurface,
GrAppliedClip&& appliedClip,
const GrDstProxyView& dstProxyView,
GrGeometryProcessor* gp,
GrPrimitiveType primType,
GrXferBarrierFlags renderPassXferBarriers,
GrLoadOp colorLoadOp) {
return CreateProgramInfo(caps,
arena,
writeView,
usesMSAASurface,
std::move(appliedClip),
dstProxyView,
gp,
this->detachProcessorSet(),
primType,
renderPassXferBarriers,
colorLoadOp,
this->pipelineFlags(),
this->stencilSettings());
}
GrProgramInfo* GrSimpleMeshDrawOpHelper::CreateProgramInfo(
const GrCaps* caps,
SkArenaAlloc* arena,
const GrSurfaceProxyView& writeView,
bool usesMSAASurface,
GrAppliedClip&& appliedClip,
const GrDstProxyView& dstProxyView,
GrGeometryProcessor* geometryProcessor,
GrProcessorSet&& processorSet,
GrPrimitiveType primitiveType,
GrXferBarrierFlags renderPassXferBarriers,
GrLoadOp colorLoadOp,
GrPipeline::InputFlags pipelineFlags,
const GrUserStencilSettings* stencilSettings) {
//创建管线
auto pipeline = CreatePipeline(caps,
arena,
writeView.swizzle(),
std::move(appliedClip),
dstProxyView,
std::move(processorSet),
pipelineFlags);
return CreateProgramInfo(caps, arena, pipeline, writeView, usesMSAASurface, geometryProcessor,
primitiveType, renderPassXferBarriers, colorLoadOp, stencilSettings);
}
const GrPipeline* GrSimpleMeshDrawOpHelper::CreatePipeline(
const GrCaps* caps,
SkArenaAlloc* arena,
GrSwizzle writeViewSwizzle,
GrAppliedClip&& appliedClip,//裁剪信息
const GrDstProxyView& dstProxyView,
GrProcessorSet&& processorSet,//生成frament shader处理器
GrPipeline::InputFlags pipelineFlags) {
GrPipeline::InitArgs pipelineArgs;
pipelineArgs.fInputFlags = pipelineFlags;
pipelineArgs.fCaps = caps;
pipelineArgs.fDstProxyView = dstProxyView;
pipelineArgs.fWriteSwizzle = writeViewSwizzle;
return arena->make<GrPipeline>(pipelineArgs,
std::move(processorSet),
std::move(appliedClip));
}
//绑定管线
bool GrGLOpsRenderPass::onBindPipeline(const GrProgramInfo& programInfo,
const SkRect& drawBounds) {
fPrimitiveType = programInfo.primitiveType();
return fGpu->flushGLState(fRenderTarget, fUseMultisampleFBO, programInfo);
}
bool GrGLGpu::flushGLState(GrRenderTarget* renderTarget, bool useMultisampleFBO,
const GrProgramInfo& programInfo) {
this->handleDirtyContext();
sk_sp<GrGLProgram> program = fProgramCache->findOrCreateProgram(this->getContext(),
programInfo);
if (!program) {
GrCapsDebugf(this->caps(), "Failed to create program!\n");
return false;
}
this->flushProgram(std::move(program));
if (GrPrimitiveType::kPatches == programInfo.primitiveType()) {
this->flushPatchVertexCount(programInfo.tessellationPatchVertexCount());
}
// Swizzle the blend to match what the shader will output.
this->flushBlendAndColorWrite(programInfo.pipeline().getXferProcessor().getBlendInfo(),
programInfo.pipeline().writeSwizzle());
fHWProgram->updateUniforms(renderTarget, programInfo);
GrGLRenderTarget* glRT = static_cast<GrGLRenderTarget*>(renderTarget);
GrStencilSettings stencil;
if (programInfo.isStencilEnabled()) {
SkASSERT(glRT->getStencilAttachment(useMultisampleFBO));
stencil.reset(*programInfo.userStencilSettings(),
programInfo.pipeline().hasStencilClip(),
glRT->numStencilBits(useMultisampleFBO));
}
this->flushStencil(stencil, programInfo.origin());
this->flushScissorTest(GrScissorTest(programInfo.pipeline().isScissorTestEnabled()));
this->flushWindowRectangles(programInfo.pipeline().getWindowRectsState(),
glRT, programInfo.origin());
this->flushConservativeRasterState(programInfo.pipeline().usesConservativeRaster());
this->flushWireframeState(programInfo.pipeline().isWireframe());
// This must come after textures are flushed because a texture may need
// to be msaa-resolved (which will modify bound FBO state).
this->flushRenderTarget(glRT, useMultisampleFBO);
return true;
}
//查找出entry,如果entry找到,首先判断entry里面是否shader,没有才进出shader的编译阶段
sk_sp<GrGLProgram> GrGLGpu::ProgramCache::findOrCreateProgramImpl(GrDirectContext* dContext,
const GrProgramDesc& desc,
const GrProgramInfo& programInfo,
Stats::ProgramCacheResult* stat) {
*stat = Stats::ProgramCacheResult::kHit;
std::unique_ptr<Entry>* entry = fMap.find(desc);
if (entry && !(*entry)->fProgram) {
// We've pre-compiled the GL program, but don't have the GrGLProgram scaffolding
const GrGLPrecompiledProgram* precompiledProgram = &((*entry)->fPrecompiledProgram);
SkASSERT(precompiledProgram->fProgramID != 0);
(*entry)->fProgram = GrGLProgramBuilder::CreateProgram(dContext, desc, programInfo,
precompiledProgram);
if (!(*entry)->fProgram) {
// Should we purge the program ID from the cache at this point?
SkDEBUGFAIL("Couldn't create program from precompiled program");
fStats.incNumCompilationFailures();
return nullptr;
}
fStats.incNumPartialCompilationSuccesses();
*stat = Stats::ProgramCacheResult::kPartial;
} else if (!entry) {
// We have a cache miss
sk_sp<GrGLProgram> program = GrGLProgramBuilder::CreateProgram(dContext, desc, programInfo);
if (!program) {
fStats.incNumCompilationFailures();
return nullptr;
}
fStats.incNumCompilationSuccesses();
entry = fMap.insert(desc, std::make_unique<Entry>(std::move(program)));
*stat = Stats::ProgramCacheResult::kMiss;
}
return (*entry)->fProgram;
}
sk_sp<GrGLProgram> GrGLProgramBuilder::CreateProgram(
GrDirectContext* dContext,
const GrProgramDesc& desc,
const GrProgramInfo& programInfo,
const GrGLPrecompiledProgram* precompiledProgram) {
TRACE_EVENT0_ALWAYS("skia.shaders", "shader_compile");
GrAutoLocaleSetter als("C");
GrGLGpu* glGpu = static_cast<GrGLGpu*>(dContext->priv().getGpu());
// create a builder. This will be handed off to effects so they can use it to add
// uniforms, varyings, textures, etc
GrGLProgramBuilder builder(glGpu, desc, programInfo);
auto persistentCache = dContext->priv().getPersistentCache();
if (persistentCache && !precompiledProgram) {
sk_sp<SkData> key = SkData::MakeWithoutCopy(desc.asKey(), desc.keyLength());
builder.fCached = persistentCache->load(*key);
// the eventual end goal is to completely skip emitAndInstallProcs on a cache hit, but it's
// doing necessary setup in addition to generating the SkSL code. Currently we are only able
// to skip the SkSL->GLSL step on a cache hit.
}
//使用 skia 自己编写的dsl编译器来生产 sksl 代码
if (!builder.emitAndInstallProcs()) {
return nullptr;
}
return builder.finalize(precompiledProgram);
}
bool GrGLSLProgramBuilder::emitAndInstallProcs() {
// First we loop over all of the installed processors and collect coord transforms. These will
// be sent to the ProgramImpl in its emitCode function
SkSL::dsl::Start(this->shaderCompiler());
SkString inputColor;
SkString inputCoverage;
//采集把之前的几何信息,拼凑到skslshader中,包括位置纹理,插值变量等
if (!this->emitAndInstallPrimProc(&inputColor, &inputCoverage)) {
return false;
}
//用来再framebuffer之间传递attachment textrue用的,简单来说就是一个framebuffer结束后的渲染结果给另一个framebuffer用
if (!this->emitAndInstallDstTexture()) {
return false;
}
//把之前写的sksl拼合进去
if (!this->emitAndInstallFragProcs(&inputColor, &inputCoverage)) {
return false;
}
//主要是对frament shader
if (!this->emitAndInstallXferProc(inputColor, inputCoverage)) {
return false;
}
//可以额外对unfiorm坐标换后处理
fGPImpl->emitTransformCode(&fVS, this->uniformHandler());
SkSL::dsl::End();
return this->checkSamplerCounts();
}
void GrGLSLProgramBuilder::finalizeShaders() {
this->varyingHandler()->finalize();
fVS.finalize(kVertex_GrShaderFlag);
fFS.finalize(kFragment_GrShaderFlag);
}
sk_sp<GrGLProgram> GrGLProgramBuilder::finalize(const GrGLPrecompiledProgram* precompiledProgram) {
TRACE_EVENT0("skia.shaders", TRACE_FUNC);
// 获取 OpenGL 程序 ID。如果有预编译程序,则使用其 ID,否则创建一个新的程序。
GrGLuint programID;
if (precompiledProgram) {
programID = precompiledProgram->fProgramID;
} else {
GL_CALL_RET(programID, CreateProgram()); // 创建新程序
}
if (0 == programID) {
return nullptr; // 如果程序 ID 无效,则返回空指针
}
// 如果支持程序二进制,且没有使用预编译程序,则启用程序二进制检索
if (this->gpu()->glCaps().programBinarySupport() &&
this->gpu()->glCaps().programParameterSupport() &&
this->gpu()->getContext()->priv().getPersistentCache() &&
!precompiledProgram) {
GL_CALL(ProgramParameteri(programID, GR_GL_PROGRAM_BINARY_RETRIEVABLE_HINT, GR_GL_TRUE));
}
// 最终化着色器
this->finalizeShaders();
// 获取着色器编译的错误处理器
auto errorHandler = this->gpu()->getContext()->priv().getShaderErrorHandler();
const GrGeometryProcessor& geomProc = this->geometryProcessor();
SkSL::Program::Settings settings;
settings.fSharpenTextures = this->gpu()->getContext()->priv().options().fSharpenMipmappedTextures;
settings.fFragColorIsInOut = this->fragColorIsInOut();
SkSL::Program::Inputs inputs;
SkTDArray<GrGLuint> shadersToDelete;
bool checkLinked = !fGpu->glCaps().skipErrorChecks();
bool cached = fCached.get() != nullptr;
bool usedProgramBinaries = false;
SkSL::String glsl[kGrShaderTypeCount];
SkSL::String* sksl[kGrShaderTypeCount] = {
&fVS.fCompilerString,
&fFS.fCompilerString,
};
SkSL::String cached_sksl[kGrShaderTypeCount];
if (precompiledProgram) {
// 处理预编译程序的缓存
this->addInputVars(precompiledProgram->fInputs);
this->computeCountsAndStrides(programID, geomProc, false);
usedProgramBinaries = true;
} else if (cached) {
TRACE_EVENT0_ALWAYS("skia.shaders", "cache_hit");
SkReadBuffer reader(fCached->data(), fCached->size());
SkFourByteTag shaderType = GrPersistentCacheUtils::GetType(&reader);
switch (shaderType) {
case kGLPB_Tag: {
// 程序二进制缓存命中
if (!fGpu->glCaps().programBinarySupport()) {
cached = false;
break;
}
reader.readPad32(&inputs, sizeof(inputs));
GrGLenum binaryFormat = reader.readUInt();
GrGLsizei length = reader.readInt();
const void* binary = reader.skip(length);
if (!reader.isValid()) {
break;
}
this->gpu()->clearErrorsAndCheckForOOM();
GR_GL_CALL_NOERRCHECK(this->gpu()->glInterface(),
ProgramBinary(programID, binaryFormat,
const_cast<void*>(binary), length));
if (this->gpu()->getErrorAndCheckForOOM() == GR_GL_NO_ERROR) {
if (checkLinked) {
cached = this->checkLinkStatus(programID, errorHandler, nullptr, nullptr);
}
if (cached) {
this->addInputVars(inputs);
this->computeCountsAndStrides(programID, geomProc, false);
}
} else {
cached = false;
}
usedProgramBinaries = cached;
break;
}
case kGLSL_Tag:
// 源代码缓存命中,直接使用缓存的 GLSL
GrPersistentCacheUtils::UnpackCachedShaders(&reader, glsl, &inputs, 1);
break;
case kSKSL_Tag:
// SkSL 缓存命中(仅在工具中覆盖生成的 SkSL 时发生)
if (GrPersistentCacheUtils::UnpackCachedShaders(&reader, cached_sksl, &inputs, 1)) {
for (int i = 0; i < kGrShaderTypeCount; ++i) {
sksl[i] = &cached_sksl[i];
}
}
break;
default:
// 如果缓存数据无效,重新验证
reader.validate(false);
break;
}
if (!reader.isValid()) {
cached = false;
}
}
if (!usedProgramBinaries) {
TRACE_EVENT0_ALWAYS("skia.shaders", "cache_miss");
// 如果缓存未命中,或者缓存中不是二进制程序
/*
片段着色器处理
*/
if (glsl[kFragment_GrShaderType].empty()) {
// 如果没有缓存的 GLSL,需编译 SkSL->GLSL
if (fFS.fForceHighPrecision) {
settings.fForceHighPrecision = true;
}
std::unique_ptr<SkSL::Program> fs = GrSkSLtoGLSL(this->gpu(),
SkSL::ProgramKind::kFragment,
*sksl[kFragment_GrShaderType],
settings,
&glsl[kFragment_GrShaderType],
errorHandler);
if (!fs) {
cleanup_program(fGpu, programID, shadersToDelete);
return nullptr;
}
inputs = fs->fInputs;
}
this->addInputVars(inputs);
// 高级过滤器处理
if (gpu()->getContext()->getProcessName() == "render_service" && fProgramInfo.pipeline().checkAFRecursively()) {
ApplyAdvancedFilter(glsl[kFragment_GrShaderType]);
}
if (!this->compileAndAttachShaders(glsl[kFragment_GrShaderType], programID,
GR_GL_FRAGMENT_SHADER, &shadersToDelete, errorHandler)) {
cleanup_program(fGpu, programID, shadersToDelete);
return nullptr;
}
/*
顶点着色器处理
*/
if (glsl[kVertex_GrShaderType].empty()) {
// 如果没有缓存的 GLSL,需编译 SkSL->GLSL
std::unique_ptr<SkSL::Program> vs = GrSkSLtoGLSL(this->gpu(),
SkSL::ProgramKind::kVertex,
*sksl[kVertex_GrShaderType],
settings,
&glsl[kVertex_GrShaderType],
errorHandler);
if (!vs) {
cleanup_program(fGpu, programID, shadersToDelete);
return nullptr;
}
}
if (!this->compileAndAttachShaders(glsl[kVertex_GrShaderType], programID,
GR_GL_VERTEX_SHADER, &shadersToDelete, errorHandler)) {
cleanup_program(fGpu, programID, shadersToDelete);
return nullptr;
}
// 绑定顶点属性位置
this->computeCountsAndStrides(programID, geomProc, true);
/*
细分着色器处理
*/
if (fProgramInfo.geomProc().willUseTessellationShaders()) {
// 细分着色器目前不支持 SkSL,这里直接生成 GLSL 字符串
SkString versionAndExtensionDecls;
versionAndExtensionDecls.appendf("%s\n", this->shaderCaps()->versionDeclString());
if (const char* extensionString = this->shaderCaps()->tessellationExtensionString()) {
versionAndExtensionDecls.appendf("#extension %s : require\n", extensionString);
}
SkString tessControlShader =
fGPImpl->getTessControlShaderGLSL(geomProc,
versionAndExtensionDecls.c_str(),
fUniformHandler,
*this->shaderCaps());
if (!this->compileAndAttachShaders(tessControlShader.c_str(), programID,
GR_GL_TESS_CONTROL_SHADER, &shadersToDelete,
errorHandler)) {
cleanup_program(fGpu, programID, shadersToDelete);
return nullptr;
}
SkString tessEvaluationShader =
fGPImpl->getTessEvaluationShaderGLSL(geomProc,
versionAndExtensionDecls.c_str(),
fUniformHandler,
*this->shaderCaps());
if (!this->compileAndAttachShaders(tessEvaluationShader.c_str(), programID,
GR_GL_TESS_EVALUATION_SHADER, &shadersToDelete,
errorHandler)) {
cleanup_program(fGpu, programID, shadersToDelete);
return nullptr;
}
}
this->bindProgramResourceLocations(programID);
// 链接程序
{
TRACE_EVENT0_ALWAYS("skia.shaders", "driver_link_program");
GL_CALL(LinkProgram(programID));
if (checkLinked) {
if (!this->checkLinkStatus(programID, errorHandler, sksl, glsl)) {
cleanup_program(fGpu, programID, shadersToDelete);
return nullptr;
}
}
}
}
// 解析程序资源位置
this->resolveProgramResourceLocations(programID, usedProgramBinaries);
// 清理临时着色器对象
cleanup_shaders(fGpu, shadersToDelete);
// 处理着色器缓存
if (!cached && !geomProc.willUseTessellationShaders() && !precompiledProgram) {
bool isSkSL = false;
if (fGpu->getContext()->priv().options().fShaderCacheStrategy ==
GrContextOptions::ShaderCacheStrategy::kSkSL) {
for (int i = 0; i < kGrShaderTypeCount; ++i) {
glsl[i] = GrShaderUtils::PrettyPrint(*sksl[i]);
}
isSkSL = true;
}
this->storeShaderInCache(inputs, programID, glsl, isSkSL, &settings);
}
// 创建并返回最终的程序对象
return this->createProgram(programID);
}
8.绑定buffer
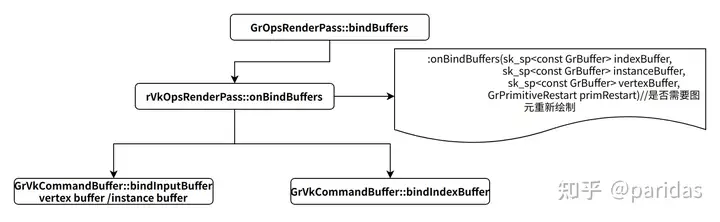
void GrGLOpsRenderPass::onBindBuffers(sk_sp<const GrBuffer> indexBuffer,
sk_sp<const GrBuffer> instanceBuffer,
sk_sp<const GrBuffer> vertexBuffer,
GrPrimitiveRestart primitiveRestart) {
SkASSERT((primitiveRestart == GrPrimitiveRestart::kNo) || indexBuffer);
// 获取当前的 OpenGL 程序对象,并确保程序有效
GrGLProgram* program = fGpu->currentProgram();
SkASSERT(program);
#ifdef SK_DEBUG
// 调试时,初始化缓冲区绑定状态为未绑定
fDidBindInstanceBuffer = false;
fDidBindVertexBuffer = false;
#endif
// 获取程序的顶点属性数量,并计算需要绑定的顶点数组状态
int numAttribs = program->numVertexAttributes() + program->numInstanceAttributes();
// 绑定内部顶点数组,并处理索引缓冲和属性数组状态
fAttribArrayState = fGpu->bindInternalVertexArray(indexBuffer.get(), numAttribs,
primitiveRestart);
// 如果有索引缓冲,且它是 CPU 缓冲区,将索引缓冲的数据指针转换为 uint16_t 类型
if (indexBuffer) {
if (indexBuffer->isCpuBuffer()) {
auto* cpuIndexBuffer = static_cast<const GrCpuBuffer*>(indexBuffer.get());
fIndexPointer = reinterpret_cast<const uint16_t*>(cpuIndexBuffer->data());
} else {
fIndexPointer = nullptr; // 如果不是 CPU 缓冲区,索引指针设为 nullptr
}
}
// 如果平台支持 baseInstance,直接绑定实例缓冲,否则推迟绑定
if (fGpu->glCaps().baseVertexBaseInstanceSupport()) {
this->bindInstanceBuffer(instanceBuffer.get(), 0); // 绑定实例缓冲
SkDEBUGCODE(fDidBindInstanceBuffer = true;) // 在调试模式下标记已绑定实例缓冲
}
fActiveInstanceBuffer = std::move(instanceBuffer); // 保存活动的实例缓冲
// 绑定顶点缓冲:根据平台是否支持 baseVertex 和是否有索引缓冲,决定绑定方式
if ((indexBuffer && fGpu->glCaps().baseVertexBaseInstanceSupport()) ||
(!indexBuffer && !fGpu->glCaps().drawArraysBaseVertexIsBroken())) {
this->bindVertexBuffer(vertexBuffer.get(), 0); // 绑定顶点缓冲
SkDEBUGCODE(fDidBindVertexBuffer = true;) // 在调试模式下标记已绑定顶点缓冲
}
fActiveVertexBuffer = std::move(vertexBuffer); // 保存活动的顶点缓冲
fActiveIndexBuffer = std::move(indexBuffer); // 保存活动的索引缓冲
}
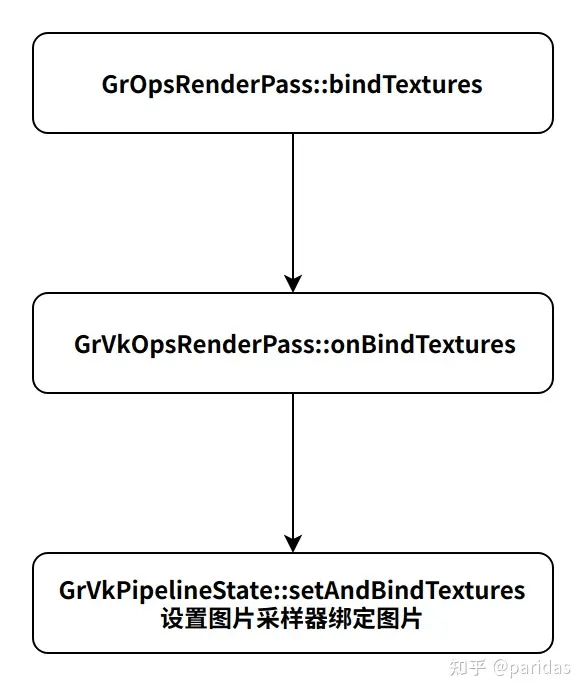
9.绑定图片
10.执行绘制
void GrOpsRenderPass::draw(int vertexCount, int baseVertex) {
if (!this->prepareToDraw()) {
return;
}
SkASSERT(!fHasIndexBuffer);
SkASSERT(DynamicStateStatus::kConfigured != fInstanceBufferStatus);
SkASSERT(DynamicStateStatus::kUninitialized != fVertexBufferStatus);
this->onDraw(vertexCount, baseVertex);
}
void GrGLOpsRenderPass::onDraw(int vertexCount, int baseVertex) {
SkASSERT(fDidBindVertexBuffer || fGpu->glCaps().drawArraysBaseVertexIsBroken());
GrGLenum glPrimType = fGpu->prepareToDraw(fPrimitiveType);
if (fGpu->glCaps().drawArraysBaseVertexIsBroken()) {
this->bindVertexBuffer(fActiveVertexBuffer.get(), baseVertex);
baseVertex = 0;
}
GL_CALL(DrawArrays(glPrimType, baseVertex, vertexCount));
}
napi_value WebGLRenderingContextBaseImpl::DrawArrays(napi_env env, GLenum mode, GLint first, GLsizei count)
{
LOGD("WebGL drawArrays mode %{public}u %{public}d %{public}d error %{public}u", mode, first, count, GetError_());
GLenum result = CheckDrawArrays(env, mode, first, count);
if (result != WebGLRenderingContextBase::NO_ERROR) {
SET_ERROR(result);
return NVal::CreateNull(env).val_;
}
glDrawArrays(mode, first, count);
LOGD("WebGL drawArrays result %{public}u", GetError_());
return NVal::CreateNull(env).val_;
}

社区规范:仅讨论OpenHarmony相关问题。
更多推荐
 2
2 3
3- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)