基于OpenHarmony的智能相册应用开发(1)
简介
相册是我们常用的应用,目前OpenHarmony社区提供的开源相册应用支持大部分基本的相册功能(如浏览、删除、收藏等)。
随着人工智能技术的兴起,我们可以在相册应用内使用机器学习模型来提供更加有用的功能,如通过文本搜索相册内的图片、自动对相册内的人脸进行聚类等。
本篇文章基于OpenHarmony社区的开源相册应用,探索如何为它增添两个基于人工智能的新功能:
- 文本搜图
- 人脸聚类
本教程的相关代码开源在这里
设计思路
为了给相册应用增加两个功能,我们首先需要考虑用什么样的机器学习模型来实现上面两个功能。
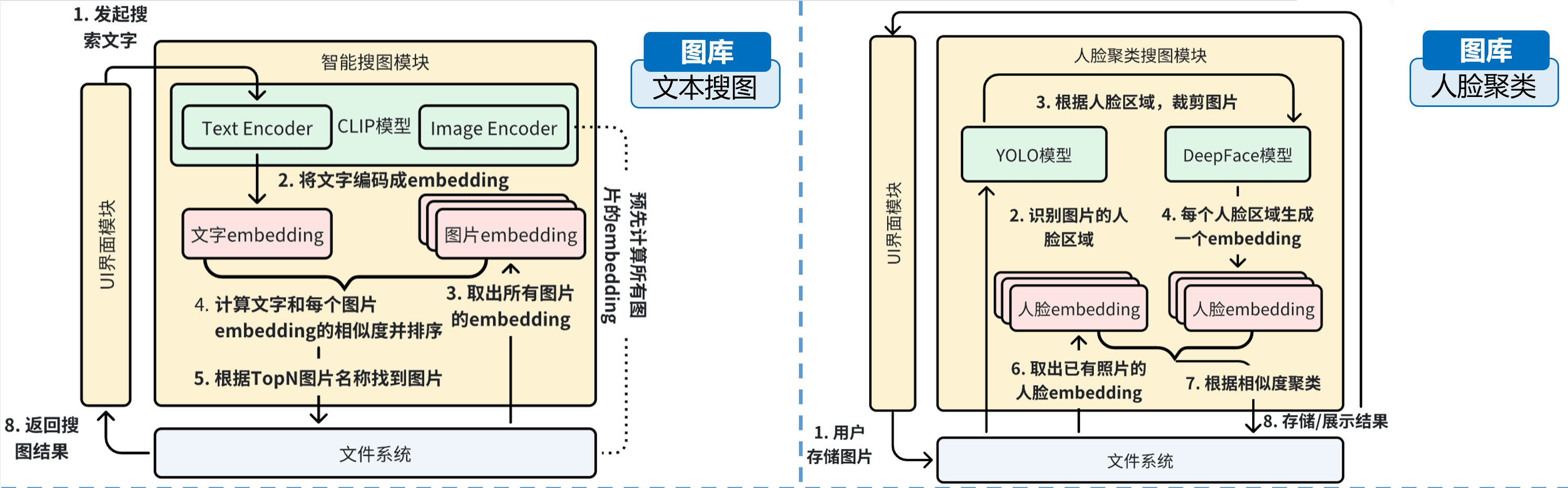
目前,文搜图领域的一个可行的模型是CLIP,它能够将文本、图片转换成相同维度的向量,两个向量越相似,那这个文本和图片对就越接近。
而人脸聚类模型方面,我们可以使用YOLO(目标检测模型)来首先识别出人脸区域在哪里,之后用另一个DeepFace模型对识别出来的区域进行向量编码,最后对人脸向量编码进行聚类分析。
应用架构
基于上述设计思路,两个功能的设计架构如下图所示:
文本搜图代码实现
首先,由于CLIP模型的推理目前只支持PyTorch,而OpenHarmony原生不支持PyTorch,因此先需要编译一份能在OH上允许的PyTorch。由于编译过程较为复杂,这里直接提供编译好的so库文件entry/libs/arm64-v8a · Zhaoguo Wang/on-device-text-image-search - 码云 - 开源中国 (gitee.com)
编译用到的CMakeList.txt文件如下所示:
# the minimum version of CMake.
cmake_minimum_required(VERSION 3.4.1)
project(ClipNative)
set(CMAKE_CXX_STANDARD 17)
set(LINK_DIRS ${CMAKE_CURRENT_SOURCE_DIR}/../../../libs/arm64-v8a)
set(PYTORCH_INCLUDE_PATH ${CMAKE_CURRENT_SOURCE_DIR}/headers/pytorch)
set(OPENCV_INCLUDE_PATH ${CMAKE_CURRENT_SOURCE_DIR}/headers/opencv/include/opencv4)
set(UTF8PROC_INCLUDE_PATH ${CMAKE_CURRENT_SOURCE_DIR}/headers/utf8proc)
include_directories(${CMAKE_CURRENT_SOURCE_DIR}
${CMAKE_CURRENT_SOURCE_DIR}/headers
${PYTORCH_INCLUDE_PATH}/include
${PYTORCH_INCLUDE_PATH}/include/torch/csrc/api/include
${OPENCV_INCLUDE_PATH}
${UTF8PROC_INCLUDE_PATH})
set(SOURCE_DIR ${CMAKE_CURRENT_SOURCE_DIR})
file(GLOB SOURCES "${SOURCE_DIR}/*.cpp" "${SOURCE_DIR}/*.c")
if (CMAKE_SYSTEM_PROCESSOR MATCHES "aarch64")
add_library(clipnative SHARED ${SOURCES})
# add_executable(clipnative ${SOURCES})
target_link_libraries(clipnative PUBLIC libace_napi.z.so)
target_link_libraries(clipnative PUBLIC hilog_ndk.z)
# Pytorch Lib
set(PYTORCH_LIBRARY "${LINK_DIRS}/libtorch_cpu.so")
set(C10_LIBRARY "${LINK_DIRS}/libc10.so")
set(PYTORCH_0_LIBRARY "${LINK_DIRS}/libtorch.so")
set(TORCH_GLOBAL_DEPS_LIBRARY "${LINK_DIRS}/libtorch_global_deps.so")
# CV Lib
set(OPENCV_CORE_LIBRARY "${LINK_DIRS}/libopencv_core.so")
set(OPENCV_IMGCODECS_LIBRARY "${LINK_DIRS}/libopencv_imgcodecs.so")
set(OPENCV_IMGPROC_LIBRARY "${LINK_DIRS}/libopencv_imgproc.so")
# utf8proc lib
set(UTF8PROC_LIBRARY "${LINK_DIRS}/libutf8proc.so")
message(PYTORCH_LIBRARY "####PYTORCH_LIBRARY####: ${PYTORCH_LIBRARY}")
message(C10_LIBRARY "####C10_LIBRARY####: ${C10_LIBRARY}")
message(PYTORCH_0_LIBRARY "####PYTORCH_0_LIBRARY####: ${PYTORCH_0_LIBRARY}")
message(TORCH_GLOBAL_DEPS_LIBRARY "####TORCH_GLOBAL_DEPS_LIBRARY####: ${TORCH_GLOBAL_DEPS_LIBRARY}")
# Pytorch
target_link_libraries(clipnative PUBLIC ${PYTORCH_LIBRARY})
target_link_libraries(clipnative PUBLIC ${C10_LIBRARY})
target_link_libraries(clipnative PUBLIC ${PYTORCH_0_LIBRARY})
target_link_libraries(clipnative PUBLIC ${TORCH_GLOBAL_DEPS_LIBRARY})
# Opencv
target_link_libraries(clipnative PUBLIC ${OPENCV_CORE_LIBRARY})
target_link_libraries(clipnative PUBLIC ${OPENCV_IMGCODECS_LIBRARY})
target_link_libraries(clipnative PUBLIC ${OPENCV_IMGPROC_LIBRARY})
# utf8proc
target_link_libraries(clipnative PUBLIC ${UTF8PROC_LIBRARY})
#target_link_libraries(clipnative PUBLIC rawfile.z)
endif()
除了PyTorch外,由于需要对图片进行预处理才可以让机器学习模型进行编码,预处理的逻辑使用OpenCV实现,因此这里也包括了OpenCV的相关库文件。
配置好CMake文件后,我们首先实现一个tokenizer,用来将文本根据词典转换成输入id,以供CLIP的文本模型进行编码使用:
#include <tokenization.h>
namespace Tokenizer {
std::wstring cleanText(const std::wstring &text) {
std::wstring output;
for (const wchar_t &cp : text) {
if (cp == 0 || cp == 0xfffd || isControol(cp))
continue;
if (isWhitespace(cp))
output += L" ";
else
output += cp;
}
return output;
}
bool isControol(const wchar_t &ch) {
if (ch == L'\t' || ch == L'\n' || ch == L'\r')
return false;
auto cat = utf8proc_category(ch);
if (cat == UTF8PROC_CATEGORY_CC || cat == UTF8PROC_CATEGORY_CF)
return true;
return false;
}
bool isWhitespace(const wchar_t &ch) {
if (ch == L' ' || ch == L'\t' || ch == L'\n' || ch == L'\r')
return true;
auto cat = utf8proc_category(ch);
if (cat == UTF8PROC_CATEGORY_ZS)
return true;
return false;
}
bool isPunctuation(const wchar_t &ch) {
if ((ch >= 33 && ch <= 47) || (ch >= 58 && ch <= 64) || (ch >= 91 && ch <= 96) || (ch >= 123 && ch <= 126))
return true;
auto cat = utf8proc_category(ch);
if (cat == UTF8PROC_CATEGORY_PD || cat == UTF8PROC_CATEGORY_PS || cat == UTF8PROC_CATEGORY_PE ||
cat == UTF8PROC_CATEGORY_PC || cat == UTF8PROC_CATEGORY_PO // sometimes ¶ belong SO
|| cat == UTF8PROC_CATEGORY_PI || cat == UTF8PROC_CATEGORY_PF)
return true;
return false;
}
bool isChineseChar(const wchar_t &ch) {
if ((ch >= 0x4E00 && ch <= 0x9FFF) || (ch >= 0x3400 && ch <= 0x4DBF) || (ch >= 0x20000 && ch <= 0x2A6DF) ||
(ch >= 0x2A700 && ch <= 0x2B73F) || (ch >= 0x2B740 && ch <= 0x2B81F) || (ch >= 0x2B820 && ch <= 0x2CEAF) ||
(ch >= 0xF900 && ch <= 0xFAFF) || (ch >= 0x2F800 && ch <= 0x2FA1F))
return true;
return false;
}
std::wstring tokenizeChineseChars(const std::wstring &text) {
std::wstring output;
for (auto &ch : text) {
if (isChineseChar(ch)) {
output += L' ';
output += ch;
output += L' ';
} else
output += ch;
}
return output;
}
std::wstring strip(const std::wstring &text) {
std::wstring ret = text;
if (ret.empty())
return ret;
size_t pos = 0;
while (pos < ret.size() && isStripChar(ret[pos]))
pos++;
if (pos != 0)
ret = ret.substr(pos, ret.size() - pos);
pos = ret.size() - 1;
while (pos != (size_t)-1 && isStripChar(ret[pos]))
pos--;
return ret.substr(0, pos + 1);
}
std::string normalize_nfd(const std::string &s) {
std::string ret;
char *result = (char *)utf8proc_NFD((unsigned char *)s.c_str());
if (result) {
ret = std::string(result);
free(result);
result = NULL;
}
return ret;
}
std::vector<std::wstring> split(const std::wstring &text) {
std::vector<std::wstring> result;
size_t pos = 0, found;
while ((found = text.find_first_not_of(stripChar, pos)) != std::wstring::npos) {
pos = text.find_first_of(stripChar, found);
if (pos == std::wstring::npos) {
result.push_back(text.substr(found));
break;
}
result.push_back(text.substr(found, pos - found));
}
return result;
}
std::wstring runStripAccents(const std::wstring &text) {
// Strips accents from a piece of text.
std::wstring nText;
try {
nText = convertToUnicode(normalize_nfd(convertFromUnicode(text)));
} catch (std::bad_cast &e) {
std::cerr << "bad_cast" << std::endl;
return L"";
}
std::wstring output;
for (auto &ch : nText) {
auto cat = utf8proc_category(ch);
if (cat == UTF8PROC_CATEGORY_MN)
continue;
output += ch;
}
return output;
}
std::vector<std::wstring> runSplitOnPunc(const std::wstring &text) {
size_t i = 0;
bool startNewWord = true;
std::vector<std::wstring> output;
while (i < text.size()) {
wchar_t ch = text[i];
if (isPunctuation(ch)) {
output.push_back(std::wstring(&ch, 1));
startNewWord = true;
} else {
if (startNewWord)
output.push_back(std::wstring());
startNewWord = false;
output[output.size() - 1] += ch;
}
i++;
}
return output;
}
bool isStripChar(const wchar_t &ch) { return stripChar.find(ch) != std::wstring::npos; }
std::vector<std::wstring> whitespaceTokenize(const std::wstring &text) {
std::wstring rtext = strip(text);
if (rtext.empty())
return std::vector<std::wstring>();
return split(text);
}
std::wstring join(const std::vector<std::wstring> &vec, const std::wstring &separator) {
std::wostringstream oss;
if (!vec.empty()) {
auto it = vec.begin();
oss << *it++;
while (it != vec.end()) {
oss << separator << *it++;
}
}
return oss.str();
}
std::shared_ptr<Vocab> loadVocab(const std::string &vocabFile) {
std::shared_ptr<Vocab> vocab(new Vocab);
size_t index = 0;
std::ifstream ifs(vocabFile, std::ifstream::in);
std::string line;
while (getline(ifs, line)) {
std::wstring token = convertToUnicode(line);
if (token.empty())
break;
token = strip(token);
(*vocab)[token] = index;
index++;
}
return vocab;
}
BasicTokenizer::BasicTokenizer(bool doLowerCase) : mDoLowerCase(doLowerCase) {}
std::vector<std::wstring> BasicTokenizer::tokenize(const std::string &text) const {
std::wstring nText = convertToUnicode(text);
nText = cleanText(nText);
nText = tokenizeChineseChars(nText);
const std::vector<std::wstring> &origTokens = whitespaceTokenize(nText);
std::vector<std::wstring> splitTokens;
for (std::wstring token : origTokens) {
if (mDoLowerCase) {
token = tolower(token);
token = runStripAccents(token);
}
const auto &tokens = runSplitOnPunc(token);
splitTokens.insert(splitTokens.end(), tokens.begin(), tokens.end());
}
return whitespaceTokenize(join(splitTokens, L" "));
}
WordpieceTokenizer::WordpieceTokenizer(const std::shared_ptr<Vocab> vocab, const std::wstring &unkToken,
size_t maxInputCharsPerWord)
: mVocab(vocab), mUnkToken(unkToken), mMaxInputCharsPerWord(maxInputCharsPerWord) {}
std::vector<std::wstring> WordpieceTokenizer::tokenize(const std::wstring &text) const {
std::vector<std::wstring> outputTokens;
for (auto &token : whitespaceTokenize(text)) {
if (token.size() > mMaxInputCharsPerWord) {
outputTokens.push_back(mUnkToken);
}
bool isBad = false;
size_t start = 0;
std::vector<std::wstring> subTokens;
while (start < token.size()) {
size_t end = token.size();
std::wstring curSubstr;
bool hasCurSubstr = false;
while (start < end) {
std::wstring substr = token.substr(start, end - start);
if (start > 0)
substr = L"##" + substr;
if (mVocab->find(substr) != mVocab->end()) {
curSubstr = substr;
hasCurSubstr = true;
break;
}
end--;
}
if (!hasCurSubstr) {
isBad = true;
break;
}
subTokens.push_back(curSubstr);
start = end;
}
if (isBad)
outputTokens.push_back(mUnkToken);
else
outputTokens.insert(outputTokens.end(), subTokens.begin(), subTokens.end());
}
return outputTokens;
}
FullTokenizer::FullTokenizer(const std::string &vocabFile, bool doLowerCase)
: mVocab(loadVocab(vocabFile)), mBasicTokenizer(BasicTokenizer(doLowerCase)),
mWordpieceTokenizer(WordpieceTokenizer(mVocab)) {
for (auto &v : *mVocab)
mInvVocab[v.second] = v.first;
}
std::vector<std::wstring> FullTokenizer::tokenize(const std::string &text) const {
std::vector<std::wstring> splitTokens;
for (auto &token : mBasicTokenizer.tokenize(text))
for (auto &subToken : mWordpieceTokenizer.tokenize(token))
splitTokens.push_back(subToken);
return splitTokens;
}
std::vector<size_t> FullTokenizer::convertTokensToIds(const std::vector<std::wstring> &text) const {
std::vector<size_t> ret(text.size());
for (size_t i = 0; i < text.size(); i++) {
ret[i] = (*mVocab)[text[i]];
}
return ret;
}
} // namespace Tokenizer
(未完待续)

社区规范:仅讨论OpenHarmony相关问题。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)