开发者手机AI - yolo数据准备
·
yolo数据准备
- 本文讲述coco数据处理成yolo格式,并且从OpenImage-V7数据集中补充分类到coco数据集的方法。用到DataHandler目录下的工具。
- coco2yolo.py: 将coco数据集标注文件处理成yolo格式。
- copy_images.py: 批量拷贝图片。
- data_convert.py: 将OpenImage数据集文件处理成yolo格式,并且拷贝图片。
- download_datasets.py: 利用 fiftyone.zoo 下载数据集。 (可以依照下载coco、VOC等数据集)
一、coco数据集预处理
注:本文仅处理coco2017的数据集。
1、下载coco数据集
2、coco数据集预处理
-
将下载的标注、训练集、验证集压缩文件分别解压。
cd ~/HDD/datasets_bak/coco unzip annotations_trainval2017.zip unzip train2017.zip unzip val2017.zip
-
将训练集、验证集标注处理成yolo格式,保存至目标路径。
python coco2yolo.py --json_path /home/ai/HDD/datasets_bak/coco/annotations/instances_train2017.json --save_path /home/ai/work/ai_doc/datasets/coco_cc/labels/train python coco2yolo.py --json_path /home/ai/HDD/datasets_bak/coco/annotations/instances_val2017.json --save_path /home/ai/work/ai_doc/datasets/coco_cc/labels/val -
将训练集、验证集图片拷贝到目标路径
python copy_images.py --origin /home/ai/HDD/datasets_bak/coco/train2017 --dest /home/ai/work/ai_doc/datasets/coco_cc/images/train python copy_images.py --origin /home/ai/HDD/datasets_bak/coco/val2017 --dest /home/ai/work/ai_doc/datasets/coco_cc/images/val
二、补充分类数据
1、定义要补充的分类配置文件 add_classes.json
修改 add_classes.json 文件, 定义要增加的分类。 key是分类名称,value对应模型中的class_id, 由于coco自己要80个分类,所以应该从80的class_id开始添加追加。
{
"Panda": 80,
"Piano": 81
}2、下载需要补充的分类
OpenImage-v7 支持1000个分类, 使用download_datasets.py工具,修改代码常量可以过滤下载所需的分类数据。
DATASET_TYPE = "open-images-v7" # 数据集类型
DATASET_ROOT = "/home/ai/HDD/datasets_bak" # 数据集下载保存的根路径
DOWNLOAD_NAME = "A2OpenImageV7" # 数据集下载的目录名称
SPLIT = ['train', 'validation'] # 数据集数据类型, train、validation、test
LABEL_TYPES = "detections" # 数据集标注类型
MAX_SAMPLE = 1000 # 符合分类过滤条件的最大样本数(download方法中未使用)运行指令, 从OpenImageV7数据集中下载Panda和Piano分类的目标检测标注训练集和验证集,保存至/home/ai/HDD/datasets_bak/A2OpenImageV7目录。
python download_datasets.py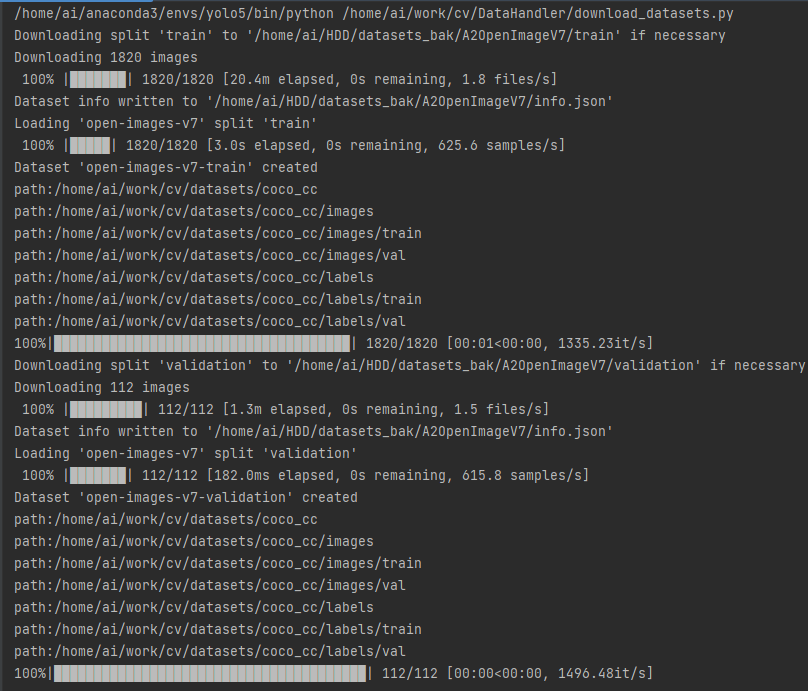
3、预处理数据成yolo格式 (已集成至downlaod_datasets.py中)
download_datasets.py代码中, 已经执行了调用data_conver.py工具。 即:
dc.convert(os.path.join(DATASET_ROOT, f"{DOWNLOAD_NAME}"), CLASSES, CUSTOM_DATA_NAME, split)3、创建新的数据yaml文件
复制 /ai_doc/yolov5-master/data/coco.yaml,更名为 coco_cc.yaml。 path修改为(数据集根目录): /ai_doc/datasets/CUSTOM_DATA_NAME train修改为(训练集): images/train val修改为(验证集): images/val test(测试集), 不需要 names(分类名称), 根据add_classes.json配置文件追加新增加的分类id和分类名称
names:
……
……
80: Panda
81: Piano
社区规范:仅讨论OpenHarmony相关问题。
更多推荐
 0
0 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)